Merge Sort was invented by John von Neumann in 1945. Many implementations have been shown in books and on the internet. However, in-place implementations have been difficult to accomplish, due to the need for an in-place merge, which only recently became available in standard C++, and is not available in other languages.
In this blog, I’ll present two simple and compact in-place sort implementations in C++, which take advantage of the availability of a standard in-place merge algorithm.
Top Down Algorithm
Top down merge sort, in-place and out-of-place, algorithms are typically implemented using divide-and-conquer approach, as shown below:
template< class _Type >
inline void merge_sort_inplace(_Type* src, size_t l, size_t r)
{
if (r <= l) return;
size_t m = l + ( r - l ) / 2; // compute average without overflow
merge_sort_inplace(src, l, m);
merge_sort_inplace(src, m + 1, r);
std::inplace_merge(src + l, src + m + 1, src + r + 1);
}This implementation is based on “Algorithms in C++” by Robert Sedgewick, p. 354, updating it with the availability of a standard C++ in-place merge algorithm. The range being sorted has also been updated to use 64-bit unsigned indexes (size_t). Computation of the mid/split index (m), has also been improved to avoid arithmetic overflow.
Bottom Up Algorithm
Bottom up algorithm has been implemented in several text books, such as “Algorithms in C++” by Robert Sedgewick, p. 360:
template< class _Type >
inline void merge_sort_bottom_up_inplace(_Type* src, size_t l, size_t r)
{
for (size_t m = 1; m <= r - l; m = m + m)
for (size_t i = l; i <= r - m; i += m + m)
std::inplace_merge(src+i, src+i+m, src + __min(i+m+m, r+1));
}This implementation has also been updated to use the standard C++ in-place algorithm, and is amazingly compact.
Performance
Both of the above In-Place Merge Sort algorithm implementations have O(n * (lgN)^2) performance, because in the worst case, the standard C++ in-place merge algorithm is O(N * lgN). However, the standard C++ implementation cleverly dynamically decides whether to use an in-place or out-of-place merge implementation under the hood. The out-of-place merge algorithm is O(N) and is much faster. It is used if enough memory is available to allocate the extra O(N) buffer of space, needed as a temporary work buffer. Otherwise, if there is not enough memory, the slower truly in-place merge algorithm is used.
Thus, if enough memory is available, the above implementations will run at O(N * lgN). But, if memory fails to allocate, it will run at O(n * (lgN)^2).
The following table shows performance sorting an array of 10 Million unsigned long integers (32-bit):
| Algorithm | Random | Presorted | Constant |
|---|---|---|---|
| Merge Sort Top Down | 9.6 | 46 | 95 |
| Merge Sort Bottom Up | 11 | 51 | 130 |
| C++ Standard sort() | 11 | 36 | 2174 |
the sorted array is first filled with either random values (uniform distribution), nearly pre-sorted values, or constant values, to provide three different distributions. Benchmark was run on Intel i7-9750H CPU.
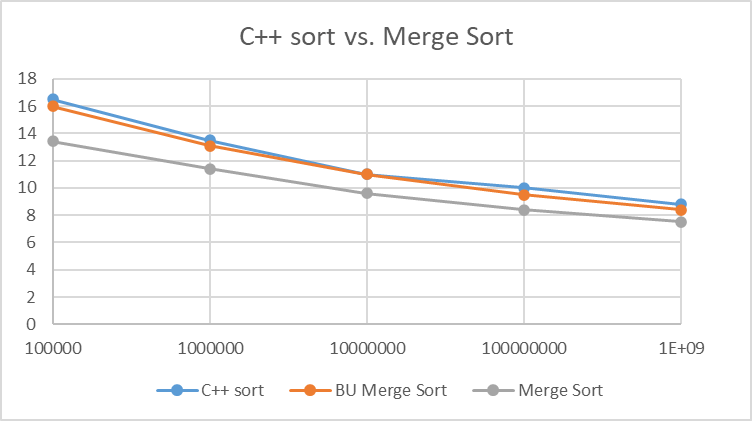
The above graph shows performance of C++ standard sort algorithm versus Merge Sort algorithms implemented above. C++ standard sort is an Introspective Sort, which is a hybrid algorithm, made of Insertion Sort, Heap Sort and Quick Sort. Both Merge Sort implementations are pure (non-hybrid) implementations.
Order of Performance
C++ standard sort performs O(N * lgN) comparisons and moves.
Both Merge Sort algorithms perform O(N * lgN) if there is sufficient memory for inplace_merge() to use not-in-place-merge version, and O(N * lg2N) when there is not sufficient extra memory available, in which case it falls back to a truly in-place merge algorithm.
The above graph shows this performance for sorting arrays of unsigned long (32-bit) integers, up to a billion of them. This benchmark was performed on a computer with 32 GBytes of system memory, which is sufficient to never cause inplace_merge() algorithm to resort to its truly in-place merge implementation. This is the reason the pure Merge Sort algorithms are competitive with C++ standard sort, as their order of performance match in that case.
Once the array gets big enough to where allocation of extra memory for inplace_merge() is not possible, and it resorts to its truly in-place merge implementation, the both Merge Sort implementations will slow down. I’ll work on benchmarking this condition, and will present performance results.
Conclusion
In this blog we saw that two simple in-place Merge Sort algorithms can be implemented using a standard C++ inplace_merge. These two implementation have competitive performance whenever enough system memory is available to allocate additional memory inplace_merge to use its higher performance not-in-place-merge algorithm implementation. inplace_merge is an adaptive algorithm – adapting its behavior and performance depending on how much system memory resource is available.
Resources
These and other sorting algorithms, including parallel/multi-core implementations are available in an open source and free C++ repo: https://github.com/DragonSpit/ParallelAlgorithms
C# implementations are available in: https://github.com/DragonSpit/HPCsharp free and open source repo and on nuget.org (HPCsharp) as a prebuilt nuget package for Windows and Linux.

One thought on “Two Simple Sorting Algorithms”