This is a re-print of my Dr. Dobb’s article from April of 2012. The original article used to be available:
https://www.drdobbs.com/parallel/benchmarking-block-swapping-algorithms/232900395
It is still available
Below is the recreated version, with code fixes to one of the algorithms.
Swapping two elements within an array quickly is simple, requiring a single temporary storage element.
template < class Item >
inline void exchange( Item& A, Item& B )
{
Item t = A;
A = B;
B = t;
}Swapping two non-overlapping subarrays of the same size is also simple.

In Figure 1, the red subarray, containing two elements, is swapped with the blue subarray, also containing two elements. The order of elements within each subarray is preserved. The two subarrays can have zero or more elements separating them. The following code implements an equal-sized non-overlapping Block Swap:
template< class _Type >
inline void swap( _Type* x, unsigned a, unsigned b, unsigned m )
{
for( ; m > 0; m-- )
exchange( x[ a++ ], x[ b++ ] );
}If the two subarrays are overlapping, an issue arises.
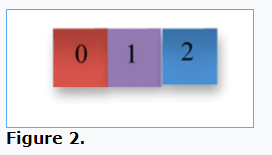
In Figure 2, the first subarray consists of elements 0 and 1, and the second consists of elements 1 and 2. Both subarrays contain element 1. The result should be as if we made copies of the two subarrays, swapped them, and then merged the result, as illustrated in Figure 3:
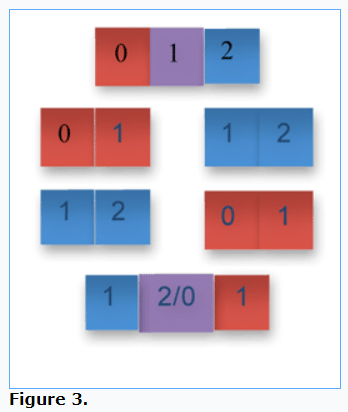
In Figure 3, the first row shows the original array with two overlapping subarrays; the second row separates the two subarrays; the third row swaps the two subarrays; and the fourth row attempts to combine the two results, leading to an ambiguity due to two possible results in the overlapping middle element.
We could define the overlapping swap operation to favor the first or the second subarray, but in either case, some array element is lost, which is be problematic because swapping is expected to preserve array elements.
Swapping two non-overlapping subarrays of any size, equal or not, is called Block Exchange, Block Swap, or Section Swap.
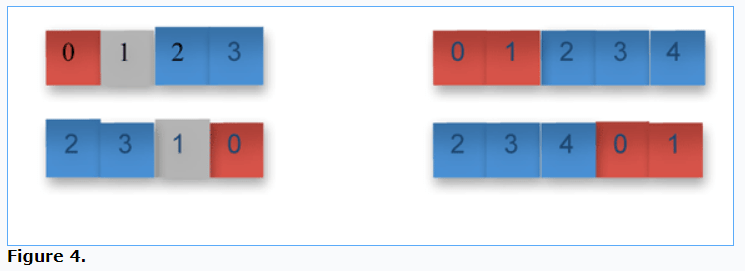
In Figure 4, in the left column, the red subarray of one element is swapped with the blue subarray of two elements, with a one separating element in grey. In the right column, the red subarray of two elements is swapped with the blue element of three elements, with no elements of separation. Note that the order of elements within each subarray is preserved.
Several algorithms have been developed to solve this problem in linear time, in-place. Some of these algorithms are easily parallelized well, while others are not. In this article, I explain these sequential algorithms and measure their performance. In upcoming articles, the algorithms will be generalized and parallelized. Finally, a general, high-performance sequential and parallel Block Exchange (Block Swap) algorithm will emerge, which will serve as a core building block for other in-place parallel algorithms.
Juggling Algorithm
Jon Bentley describes three algorithms for Block Exchange in his book, Programming Pearls, (pp. 13-15, 209-211) and in an oft-cited article [PDF]. Figure 5 shows how the first of these, the Juggling algorithm, works. The first row is the starting array, where the red subarray of two elements and the blue subarray of four elements are to be swapped. The last row is the result, and each row is a step of the algorithm:
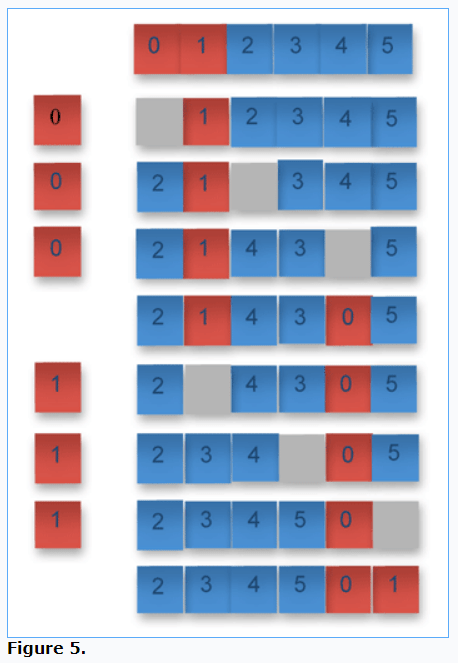
The column on the left shows the single element of the extra storage space used to support its in-place capability. Element 0 is moved to this extra storage space, leaving a hole within the array (the second row of the illustration). In the third row, element 2 is moved into the hole, leaving a new hole. In row four, element 4 is moved into the hole, leaving a new hole. In row five, wrap-around occurs forming a loop, landing on element 0, which is retrieved from the extra storage space. In row six, a new loop is started at element 1, following the same steps. Bentley’s Juggling algorithm implementation is shown in Listing One:
// Juggling algorithm for block swapping.
// Greatest Common Divisor. Assumes that neither input is zero
inline int gcd( int i, int j )
{
if ( i == 0 ) return j;
if ( j == 0 ) return i;
while ( i != j )
{
if ( i > j ) i -= j;
else j -= i;
}
return i;
}
template< class _Type >
inline void block_exchange_juggling_Bentley( _Type* a, int l, int m, int r )
{
int u_length = m - l + 1;
int v_length = r - m;
if ( u_length <= 0 || v_length <= 0 ) return;
int rotdist = m - l + 1;
int n = r - l + 1;
int gcd_rotdist_n = gcd( rotdist, n );
for( int i = 0; i < gcd_rotdist_n; i++ )
{
// move i-th values of blocks
_Type t = a[ i ];
int j = i;
while( true ) {
int k = j + rotdist;
if ( k >= n )
k -= n;
if ( k == i ) break;
a[ j ] = a[ k ];
j = k;
}
a[ j ] = t;
}
}Rotation distance (Ρ) is the greatest common devisor (gcd) of the length of the first subarray and the length of the entire array. The algorithm makes Ρ number of loops — the limit on the for loop (gcd_rotdist_n). Within each loop n/Ρ elements are moved by Ρ elements to the left. The algorithm has linear time performance because each element of the array is moved once by the rotation distance. The number of loops is between one and the length of the left subarray. Note that swapping is not used, but instead, the elements are moved in a similar fashion to the efficient implementation of Insertion Sort.
Gries and Mills Block Swapping
Bentley also describes a block-swapping algorithm by Gries and Mills in his book and the article. The algorithm swaps the largest equal-sized non-overlapping blocks available at each step. The main idea is to use swap as an operation as follows from his article:
- A is the left subarray, B is the right subarray — that is, the starting point is AB
- If A is shorter, divide B into BL and BR, such that length of BR equals the length of A
- Swap A and BR to change ABLBR into BRBLA
- Recur on the two pieces of B
- Once A and B are of equal lengths, swap A and B
Figure 6 shows the steps:
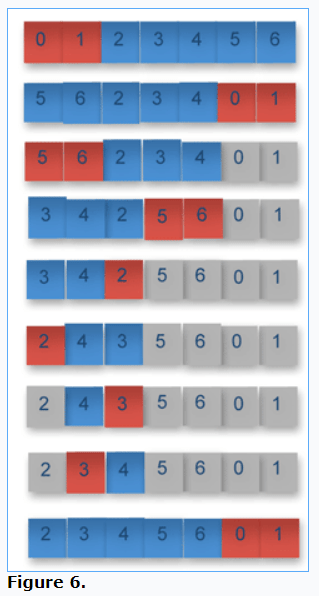
Red indicates the shorter of the two subarrays. The red subarray is A, and the blue subarray is B. The length of A is two, which is shorter than the length of B, which is five, and B is divided into BL and BR, where BR is of equal length to A. At this point BR contains elements 5 and 6. A and BR are swapped, which is shown in the second row.
In the third row, the original A subarray (elements 0 and 1) is at its final location, shown in grey. The smaller of the BL and BR is colored red, and the next level of recursion proceeds with these two subarrays. Elements 5 and 6 become the red subarray A, and the blue subarray of elements 2, 3 and 4 becomes B. Since A is shorter than B, the subarray B is split into BL and BR consisting of elements (2) and (3 and 4), respectively. In row four, subarrays A and BL are swapped. The algorithm continues to recurse, until the remaining subarrays are of the same size, at which point they are swapped. The Gries-Mills Swap non-recursive implementation is shown in Listing Two:
template< class _Type >
inline void swapABLength(_Type* x, int a, int b, int length)
{
while (length-- > 0)
{
_Type temp = x[a];
x[a++] = x[b];
x[b++] = temp;
}
}
template< class _Type >
inline void block_swap_Gries_and_Mills(_Type* a, int l, int m, int r)
{
int rotdist = m - l + 1;
int n = r - l + 1;
if (rotdist == 0 || rotdist == n) return;
int p, i = p = rotdist;
int j = n - p;
p += l;
while (i != j)
{
if (i > j)
{
swapABLength(a, p - i, p, j);
i -= j;
}
else {
swapABLength(a, p - i, p + j - i, i);
j -= i;
}
}
swapABLength(a, p - i, p, i);
}
Reversal Algorithm
The third algorithm Bentley describes is the Reversal, which is the simplest. The Reversal algorithm uses rotation as the operation instead of swap. Figure 7 shows the steps:

The first row is the original array, where the red and the blue subarrays are to be exchanged. In the second row, the elements of the red array are rotated. Rotation is an operation that can be done in-place for any number of elements (odd or even), reversing the order of elements within an array. In the third row, the elements of the blue subarray are rotated. Going from the third row to the last row, the entire array is rotated, resulting in the red and blue subarrays being exchanged. The implementation is shown in Listing Three.
// reverse/mirror a range from l to r, inclusively, in-place
template< class _Type >
inline void reversal( _Type* a, int l, int r )
{
while( l < r ) exchange( a[ l++ ], a[ r-- ] );
}
// Swaps two sequential subarrays ranges a[ l .. m ] and a[ m + 1 .. r ]
template< class _Type >
inline void block_exchange_reversal( _Type* a, int l, int m, int r )
{
reversal( a, l, m );
reversal( a, m + 1, r );
reversal( a, l, r );
}The inverse variation on this method rotates the whole array, followed by the rotations of the two subarrays, as shown in Figure 8:
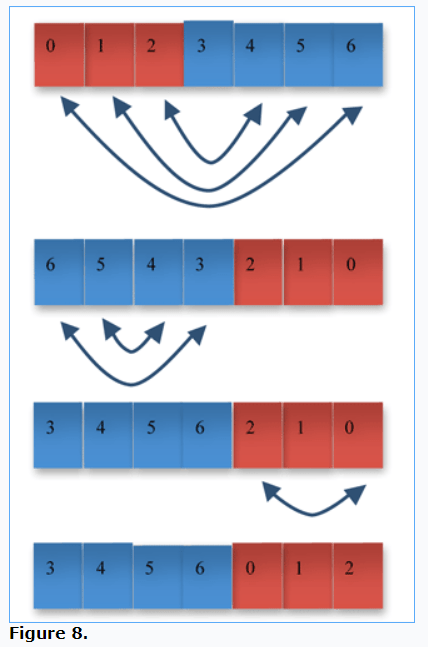
Going from the first row to the second, the entire array is rotated. At this point, the blue and red subarrays are in their proper places, but each are in reverse order. In the third row, the blue subarray is rotated. In the last row, the red subarray is rotated. The result is a red and blue block exchange. Listing Four shows an implementation of this method.
template< class _Type >
inline void block_exchange_reversal_reverse_order( _Type* a, int l, int m, int r )
{
reversal( a, l, r );
int m_in_destination = r - ( m - l + 1 );
reversal( a, l, m_in_destination );
reversal( a, m_in_destination + 1, r );
}Benchmarks and Constants
Bentley benchmarked these algorithms on a 400 MHz Pentium II, varying the size of the smaller subarray from 1 to 50, with an overall array of 1 million elements. He found that the Reversal algorithm averaged near 66 nanoseconds per element, Gries-Mills was below 50 ns per element, and the Juggling algorithm was about 190 ns per element. Today’s processors, such as the Intel i7 860, run at 2.8 GHz (with TurboBoost, up to 3.46 GHz) and provide larger multilevel caches with automatic prefetching.
Table 1 shows statistics gathered from performance measurements for an input array of 1 million 32-bit elements, split into two subarrays of all possible sizes, which are then Block Exchanged using each of the three algorithms. The code was compiled with Intel C++ Composer XE 2011.

From these performance measurements, the Gries-Mills algorithm has retained its performance lead, with the highest mean performance of 1.22 ns/element, the fastest worst case, and the smallest range. The Reversal algorithm came in at a close second place, with the smallest standard deviation and same range; that is, the most consistent performance. The Juggling algorithm’s performance is substantially worse, more than 5x slower than Gries-Mills, with deviation 14x worse, and over 5x the range. The performance gain is substantially higher than the frequency ratio would account for (3.46 GHz/400 MHz = 8.7x), whereas the Gries-Mills algorithm gained over 40x in performance. Thus, CPU and memory improvements other than frequency provided over 4x the performance gain.
The Reversal algorithm performs |A|/2 swaps in the first step, |B|/2 swaps in the second step, and (|A|+|B|)/2 swaps in the third step, where |A| is the number of elements in the A subarray, for a total of (|A|+|B|) swaps. Since (|A|+|B|) = N, the Reversal performs N swaps. Each swap performs 3 memory reads and 3 memory writes for a total of 6N memory accesses.
The Gries-Mills algorithm performs S = min(|A|,|B|) swaps at each iteration of the algorithm, for N/S iterations, until fewer than |A| elements remain. The total number of swaps can be approximated by N/S iterations times S swaps, which is N swaps, which is 6N memory accesses.
The Juggling algorithm moves array elements instead of swapping them, which uses a single read and a single write. In the best case of handling all array elements in a single loop, 2*(N+1) memory accesses are needed. However, in the worst case, when each pair of elements terminates a loop, the Juggling algorithm, performs N/2 swaps, as it moves an element into the temporary storage location, then moves a single element into its destination, followed by a move from the temporary storage location to its destination. In the worst case, the Juggling algorithm performs 3N memory accesses. Thus, the number of memory accesses is between 2N and 3N for the Juggling algorithm.
The three algorithms are O(n). From the number of memory accesses, the Juggling algorithm should have the highest performance, as it performs between 2x and 3x fewer memory accesses. Performance measurements show the Juggling algorithm being the slowest, however. The Reversal and Gries-Mills algorithms access memory within the array in a highly coherent way: The next array element accessed is the left or the right neighbor of the current element. This memory access pattern is cache friendly, resulting in higher performance.
The Juggling algorithm accesses memory in a non-cache-friendly manner, suffering in performance for it. When the rotation distance (Ρ) is 1, the algorithm accesses the neighboring element. As the rotation distance increases, the percentage of cache line hits decreases proportional to the distance. Once the distance exceeds the cache line size, the next element accesses become cache misses, which are much slower than cache hits.
The importance of algorithmic cache-friendliness on swapping algorithms has increased from Pentium II to the present-day Intel i7 860 processor, as the ratio between the best and the worst performance of these algorithms increased from nearly 4x on the Pentium II to over 5x today. The number of memory accesses used by an algorithm does not necessarily provide a good estimate of performance: Knowledge of whether the accesses are cache hits or misses is also necessary.
A swap operation performs a total of 3 reads and 3 writes. Out of these, only two reads and two writes are from/to system memory (at 32-bits each). Thus, 4 accesses * 4 bytes/1.22 ns/element = 13.1 GBytes/sec of memory bandwidth. System memory consists of two channels that are 64-bits each and run at 1333 MHz, for a peak bandwidth of 21.3 GBytes/sec. Thus, the Reversal algorithm is using 62% of the total memory bandwidth from a single CPU core, which doesn’t provide much headroom for parallel scaling.
Conclusion
Three sequential O(n) in-place algorithms for swapping/exchanging blocks of unequal sizes were explored. The Gries-Mills algorithm is the performance leader with the Reversal algorithm coming in a close second, and the Juggling algorithm a distant third. The Reversal algorithm is the gem of the three, having high and consistent performance, the smallest and simplest implementation, and being the easiest to understand. The Gries-Mills and Reversal algorithms performed well due to their cache-friendly memory access patterns. The Juggling algorithm performed the fewest memory accesses, but came in over 5x slower due to its cache-unfriendly memory access pattern.
Victor Duvanenko is a frequent contributor to Dr. Dobb’s on algorithms for parallel programming.
