This blog is a re-post of my Dr. Dobb’s Journal article in February of 2011. All of the source code, including a working VisualStudio 2022 solution with examples is on GitHub along with the Parallel Merge implementation. Parallel Merge Sort has also been developed.
Another resource is a recently published Parallel Algorithms in C++ and C# Book which describes Parallel Merge along with other parallel sorting algorithms.
For the next several articles in this series, we’ll explore parallel and sequential merge algorithms. We’ll utilize Intel Threading Building Blocks as well as Microsoft Parallel Patterns Library (PPL), which is part of Visual Studio 2010. We’ll implement several different parallel and sequential merge algorithms, and investigate their performance on today’s multicore processors. In this article, we’ll leap right into a very interesting parallel merge, see how well it performs, and attempt to improve it.
Merge
Merge is a fundamental operation, where two sets of presorted items are combined into a single set that remains sorted. For example, given two sets of integers
5, 11, 12, 18, 20
2, 4, 7, 11, 16, 23, 28
The resulting merged set is
2, 4, 5, 7, 11, 11, 12, 16, 18, 20, 23, 28
The first set has five elements, whereas the second set has seven, and the result set has twelve. Merge does not require the source sets to be of equal size. Merge can operate on two input arrays, and produce an output array. The output array has to be large enough to hold the result, which is generated in O(n) time.
Listing One in GitHub/ParallelAlgorithms/ParallelMerge.h shows a simple sequential merge algorithm implementation, where two read-only input arrays of different sizes are merged into a single output array. The input arrays must be presorted, monotonically incrementing. The resulting output array will also be incrementing.
The first if statement compares the first element from a[] array and the first element from b[]array, outputting whichever is smaller, with ties choosing the element from a[] to retain stability. Each array has a pointer that keeps track of the current position within that array. Only the pointer of the source array that is output gets incremented. When the current position of either array goes past the end of that array, the first while loop terminates. When all of the elements from one of the arrays have been used, the other array may still have elements left. At that point, comparisons between input arrays are no longer possible. The second and third while loops output any remaining elements.
Merge is O(n), where n is the number of output elements, since one element is output during each iteration of the while loop(s). More complex merges support more than two input arrays, in-place operation, and can support other data structures such as linked lists.
Divide-and-Conquer Merge
The aforementioned sequential merge algorithm does not parallelize in an obvious fashion. Divide-and-conquer algorithms typically parallelize well. Merge is tricky since it’s O(n) and making the order worse is not desirable. In other words, we want an O(n) or better divide-and-conquer merge algorithm. The authors of the latest (3rd edition) Introduction to Algorithms book [1] develop, describe and analyze such an algorithm, in the new chapter on multithreaded algorithms. Listing Two shows a direct translation of the pseudocode parallel implementation into sequential C++ implementation. A binary search algorithm is also shown, which is a translation of the pseudocode on p. 799. Figure 1 illustrates how the algorithm works by showing the process within one level of recursion.
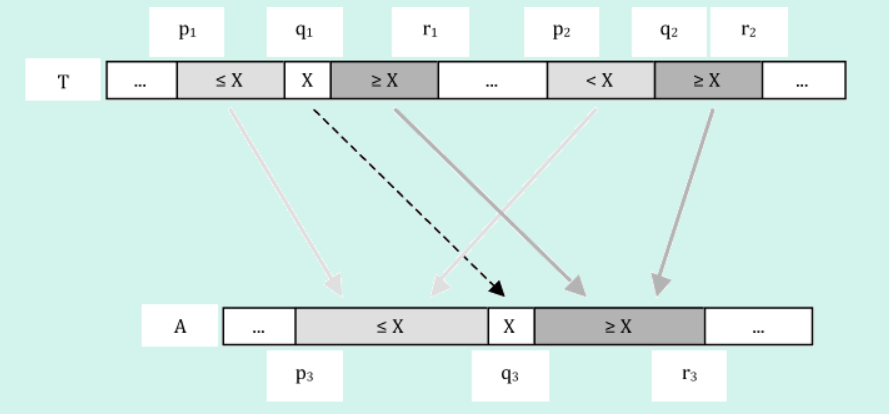
The input to the divide-and-conquer merge algorithm comes from two sub-arrays of T, and the output is a single sub-array A. The two input sub-arrays of T are from [p1 to r1] and from [p2to r2]. The output sub-array of A is from [p3 to r3]. The divide step is done by choosing the middle element of the larger of the two input sub-arrays (at index q1 in Figure 1 and in Listing Two) . The value at this index is then used as the partition element to split the other input sub-array into two sections — less than X in Figure 1 and greater than or equal to X. The partition value X (at index q1 of T) is copied to array A at index q3. The conquer step recursively merges the two portions that are smaller than or equal to X — indicated by light gray box and arrow shading. It also recursively merges the two portions that are larger than or equal to X — indicated by darker gray box and arrow shading.
The algorithm proceeds recursively until the termination condition — when the shortest of the two input sub-arrays has no elements. At each step, the algorithm reduces the size of the array by one element. One merge is split into two smaller merges, with the output element placed in between. Each of the two smaller merges will contain at least N/4 elements, since the left input array is split in half.
The algorithm is stable, because each recursion step is stable. At each step, the elements of the left array are smaller (or equal to) the elements of the right array. When the split is made using the mid-left element, only right array elements that are strictly less than the split element (X) are used in the subsequent right smaller merge, which is the crucial step ensuring stability.
Table 1 and Graph 1 show performance measurements for merging of two random input arrays that are pre-sorted, using the simple merge, STL merge, and divide-and-conquer merge.

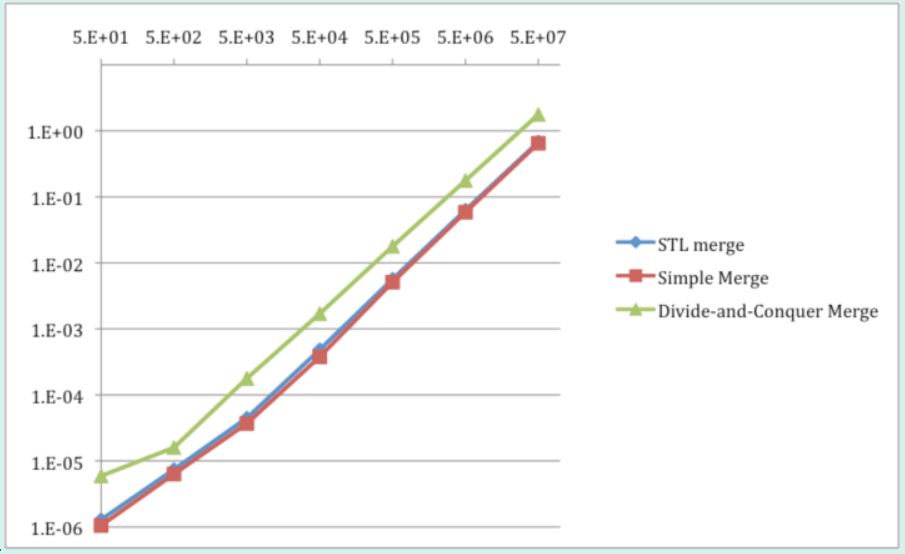
The simple merge and STL merge algorithms are always faster than the divide-and-conquer merge algorithm, by 2-5 times. Performance measurements confirm all algorithms to be linear. The number of items in Table 1 and Graph 1 indicates the size of each of the two input arrays (of equal size), producing the resulting array of twice that size. Each item is a 32-bit unsigned number. Thus, the simple merge algorithm outputs items at a rate of 153 Million/second. The total memory bandwidth is 1.2 GB/second for reads and writes.
Parallel Merge
Transforming the divide-and-conquer sequential merge algorithm into a parallel algorithm turns out to be very simple when using Microsoft Parallel Pattern Library (PPL) or Intel Threading Building Blocks (TBB) along with C++ lambda functions. Lambda functions are new to C++, and are part of C++0x standard, which is supported by Microsoft VisualStudio 2010 and Intel C++ Compiler.
Listing Three shows the initial parallel implementation for both PPL and TBB, which are identical except for the namespace — Concurrency:: for PPL, and tbb:: for TBB. Parallel function parallel_invoke() is used to implement concurrency in both libraries. Multiple functions are passed as arguments to parallel_invoke(), which evaluates them possibly in parallel.
Lambda functions simplify the code by enabling the functions to be defined in-place. The [&]indicates that all arguments to the function are to be by-reference. parallel_invoke() is a good choice for this algorithm because it allows for complete control over the range of the input and output array, which is needed by the algorithm. Other parallel functions, such as parallel_reduce() and parallel_for() generate array ranges “automagically,” which makes them useful in other cases (as shown in previous parts of this series). Table 2 and Graph 2 show performance measurements for two sequential and two parallel implementations: simple merge, divide-and-conquer merge, PPL parallel merge, and TBB parallel merge.


Both parallel divide-and-conquer implementations perform poorly and are several times slower than the sequential implementations. These parallel implementations running on four cores are up to 29-69 times slower than the simple merge sequential algorithm running on a single core. This is a substantial performance gap to close. However, so far only pure algorithms have been utilized, and is a good time to mix things up.
Hybrid Approach
In previous articles of this series, the hybrid algorithm approach was used to accelerate performance of several sequential and parallel algorithms. Since the simple merge is faster than the divide-and-conquer algorithm for merging small arrays, it could be used to terminate recursion early to handle small merges. Listing Four shows the hybrid divide-and-conquer merge algorithm.
Table 3 shows performance measurements for the sequential pure and hybrid divide-and-conquer merge algorithm implementations, with varied threshold value (shown in parenthesis) of switching between divide-and-conquer and the simple merge algorithm.

The hybrid approach substantially accelerates performance of sequential divide-and-conquer algorithm. As the threshold value is increases, the performance also increases. For threshold of 32 acceleration is 2-3 times, whereas threshold of 8192 increased performance by 5-10 times. The hybrid divide-and-conquer sequential merge algorithm even outperforms the sequential merge algorithm, which seems incorrect and should be investigated in the future (it seems the performance should approach that of the simple merge).
For parallel algorithms, grain size has been shown as one of the key performance parameters. Grain size is the minimum amount of work that is worthwhile to perform in parallel as a task. Parallel tasks may get moved between cores, which has a finite overhead cost (takes finite time). Thus, parallel tasks must be large enough to keep this overhead as a small percentage of overall work being performed. This is the main reason that the aforementioned pure parallel algorithm performance is poor — the grain size is potentially as small as a single array element, which is too small to be executed efficiently in parallel. Intel TBB recommends keeping the grain size at more than 10K CPU clock cycles. The hybrid algorithm approach works well for this issue (as we’ve seen in previous articles of this series). Listing Five shows the hybrid divide-and-conquer parallel merge algorithm.
Tables 4 and 5 show performance measurements for two pure and hybrid parallel hybrid divide-and-conquer merge algorithm implementations, with the varied threshold value (shown in parenthesis) of switching between divide-and-conquer and the simple merge algorithm.
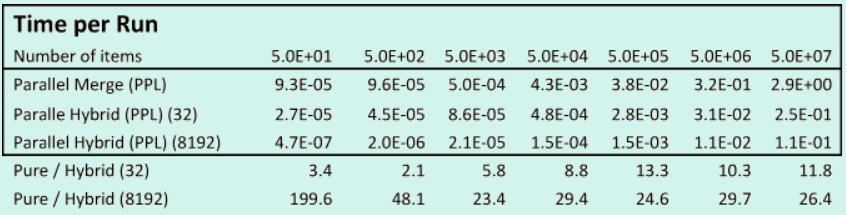

The hybrid approach also substantially accelerates performance of parallel divide-and-conquer algorithms. As the threshold value is increases, the performance also increases. For a threshold of 32, acceleration is 2-15 times; whereas a threshold of 8192 increased performance over 20 times. The parallel hybrid divide-and-conquer merge algorithm is the highest-performance algorithm developed.
The hybrid algorithm approach works well for the following reason. A pure divide-and-conquer merge algorithm splits the two input arrays recursively, creating a binary recursion tree, until one of the arrays has no elements. The algorithm performs a fair amount of computation during each recursion, while outputting a single array element. A hybrid algorithm approach terminates the recursion tree earlier, set by the threshold, and uses the faster simple merge algorithm to process merges of small arrays. The faster simple merge performs very little work per output element.
In the hybrid approach, some of the work is performed by the divide-and-conquer, and some of the work is performed by the simple merge. The threshold specifies how small the input arrays need to be to switch to using the simple merge algorithm. As the threshold is increased, the amount of work performed by the simple merge increases, which brings performance closer to the performance of the simple merge. The resulting hybrid algorithm has the performance of the simple merge, but retains the divide-and-conquer structure to enable parallelism.
The hybrid approach also improves memory access pattern of the divide-and-conquer algorithm, since the simple merge reads and writes memory sequentially, whereas the pure divide-and-conquer algorithm does not.
The two parallel merge implementations (PPL and TBB) benefit from the hybrid approach also by having a larger parallel grain size — a larger parallel work quanta. When tasks perform work, it’s big enough to keep the overhead of task switching negligible. Thus, hybrid parallel merge benefits from a larger grain size and from combining with the faster simple merge. The PPL implementation speedup is 23-48 times, and TBB speedup is 20-58 times.
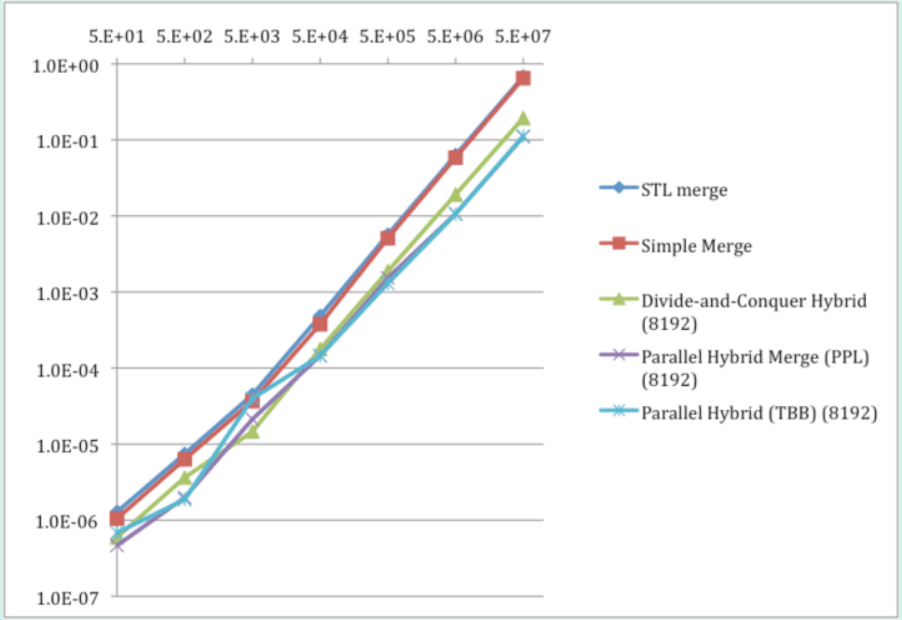
Table 6 and Graph 3 compare performance of the best sequential and parallel merge algorithms developed in this article.

Conclusion
Parallel hybrid merge algorithm was developed that outperformed sequential simple merge as well as STL merge by 0.9-5.8 times overall and by over 5 times for larger arrays, running on a quad-core processor. The pure parallel merge algorithm was shown to perform poorly — substantially slower than the simple sequential merge.
Microsoft PPL and Intel TBB technologies were used for parallel algorithm development, with comparable performance and identical implementations, simplifying development significantly. Lambda functions were used to simplify the parallel implementation.
A parallel algorithm may use a different strategy than a sequential algorithm. The simple sequential merge iterated through the two input arrays, while the parallel divide-and-conquer algorithm split the problem into two sub-problems recursively.
Pure divide-and-conquer sequential and parallel algorithms failed to deliver competitive performance due to large computational overhead per output element and large task-switching overhead. Simple merge has a small constant as it performs little work per output element. The hybrid algorithm approach yielded performance gains for sequential and parallel merge algorithms. For sequential merge, the hybrid divide-and-conquer algorithm outperformed the simple merge algorithm, which seems questionable.
For parallel algorithms, divide-and-conquer proved to be a good strategy, especially coupled with the hybrid approach, enabling parallel processing with high performance. A fast sequential merge was shown to be a critical component of the fast parallel hybrid algorithm.
The hybrid algorithm improved the memory access pattern of the divide-and-conquer algorithm. Pure divide-and-conquer has a nonsequential memory access pattern. The hybrid approach used the simple merge, which has incrementing memory addressing for both inputs and the output. The hybrid parallel algorithm approach provided over 20 times the performance gain over the pure parallel divide-and-conquer algorithm. Otherwise, the pure parallel algorithm was measured to be slower than the simple sequential merge.
As long as task-switching overhead continues to be fairly high, a high-performance parallel algorithm will require a high-performance sequential algorithm to use as a recursion termination case or within the minimal parallel work quanta.
The sequential simple merge algorithm measured at 1.2 GB/second of memory bandwidth. The parallel hybrid merge algorithm used about 7.1 GB/second, nearing the memory bandwidth limit for scalar code, and possibly limiting performance.
References
[1] T.H. Cormen, C.E. Leiserson, R.L. Rivest, and C. Stein, Introduction to Algorithms, Third Edition, MIT Press, Sept. 2009, pp. 797-805

2 thoughts on “Parallel Merge”