This blog is a re-post of my Dr. Dobb’s Journal article from March of 2011. All of the source code, including a working VisualStudio 2022 solution with examples is on GitHub along with Parallel Merge Sort implementation.
Another resource is a recently published Parallel Algorithms in C++ and C# Book which describes Parallel Merge Sort and other parallel sorting algorithms.
In last month’s article in this series, a Parallel Merge algorithm was introduced and performance was optimized to the point of being limited by system memory bandwidth. Of course, the natural next step is to use it as a core building block for Parallel Merge Sort, since Parallel Merge does most of the work. Let’s leap right in and explore this Parallel Merge Sort algorithm.
Simplest Parallel Merge Sort
GitHub/ParallelAlgorithms/ParallelMergeSort.h shows the simplest Parallel Merge Sort implementation, which uses the Parallel Merge. At the core, the algorithm takes the input range (l to r), computes the mid-point (m), calls itself recursively twice — once with the lower half range, and the second time with the upper half range — followed by merging the two resulting sorted halves into a single output. This is exactly how the standard Merge Sort works — divide, conquer, and merge. Parallelism comes from executing the two recursive calls in parallel, followed by a parallel merge. The amount of parallelism is Θ(n/lg2n), derived in [1].
Graph 1 and Table 1 show performance of the simplest parallel merge sort implementation as compared with STL sort and stable_sort. X-axis is array size, and Y-axis is time in seconds to sort the array.


STL stable_sort is slower than STL sort, as expected — it takes more effort and time to ensure stability. The simplest Parallel Merge Sort implementation outperforms both STL sorts for arrays larger than about 10K elements. Parallel Merge Sort is stable, and is as much as 3.5X faster than STL stable_sort, and is as much as 2.7X faster than STL sort, on a quad-core processor.
Reversals
The Parallel Merge Sort is not an in-place algorithm. Source array elements are sorted and the result is placed in the destination array. Note that the last argument to the recursive function specifies the direction, with the default being “from the source to the destination,” which is set at the top-level of recursion. Then at each level of recursion the direction is reversed. Figure 2 illustrates this directional reversal at each recursion level of the call tree.
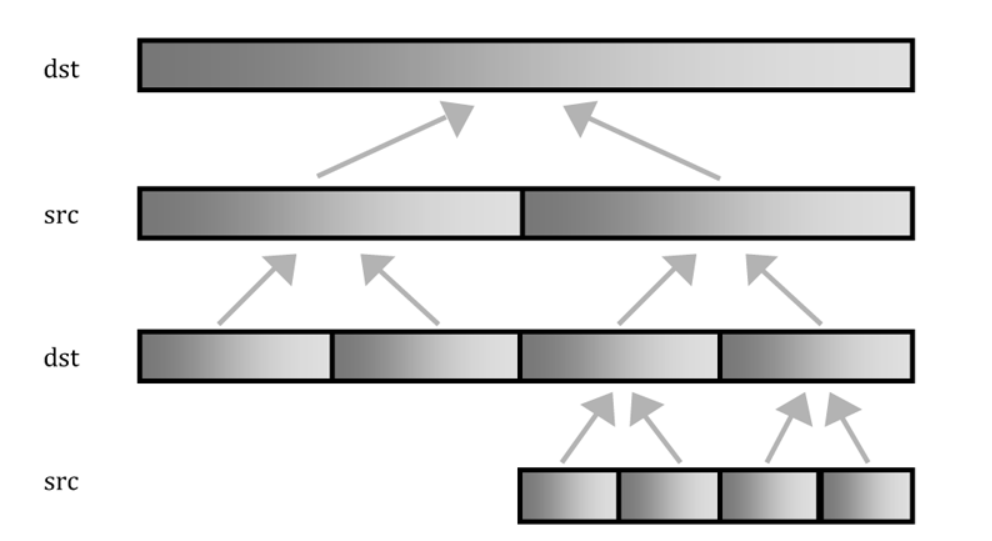
At the top level of recursion hierarchy the sorted destination (dst) array is produced by merging two sorted source (src) arrays. During this merge operation elements are moved from the source (src) array to the destination array. At the next level, the sorted source (src) array is produced by merging two sorted destination (dst) arrays. This continues until the bottom of the hierarchy is reached with only a single element in the array to be processed.
The termination condition (base case) handles the two possible cases at this point:
- By doing nothing if the destination array is
src. In this case, we are sorting a single element that was provided in thesrcarray and are asked to place the result back in thesrcarray. With a single element, there is nothing to do when sorting it, and it’s already in thesrcarray. So, we just leave it there. - By copying that single element from the
srcarray to thedstarray. In this case, we are sorting a single element that was provided in thesrcarray and are asked to place the result in thedstarray. With a single element there is nothing to do when sorting it. To place it in thedstarray we simply copy it.
The recursive implementation in Listing 1 does not handle the condition of zero elements in the input array, which is signified by r being smaller than l. The implementation could test for this case, but it would be wasteful as it can never be generated by the recursive implementation (and can only be generated by the user on the initial function call). So, for the sake of efficiency and simplicity, the check for zero size array is pulled out into a wrapper function shown in Listing Two. Actually, this is also the reason for l and r being int‘s instead of unsigned long. For example, for an array of zero elements, argument l would be set to zero, requiring r to be set to -1, which can be done using an int but not unsigned long. This issue can probably be avoided by using a pointer to the start of each array and to the one-beyond-the-end of each array or iterators as STL does, instead of indexes. Another option is to use a pointer and an array size as function call arguments.
This implementation is a variation on that presented in the Introduction to Algorithms book [1]. By using direction reversal, memory allocation operations have been eliminated.
Dual Usage
The Parallel Merge Sort algorithm implementation in Listing 1 takes an input src array and places the result in the output dst array, with the direction specified by the srcToDst argument set to true. This usage may not be convenient at times, and in-place usage may be desirable. In other words, sometimes we may want the input to sorting to come from the src array, and the result of sorting to be placed back in the src array. We could just copy from the dst array back into the src array after sorting, but that takes extra time and extra code. Wouldn’t it be nice if we could just tell the Parallel Merge Sort function to place the result back in the src — i.e., set srcToDst = false.
Surprisingly, this works!
Figure 3 illustrates this scenario. It helps to look at the recursion termination base case code, where the magic happens. The base case just does the right thing. It knows that the input array data only exists in the src array.

Thus, the algorithm implementation also handles the use case of the input array coming from src, the output being place back in src, and dst being an auxiliary array needed by the sorting algorithm for intermediate results. It is pretty amazing that a single algorithm implementation handles both of these use cases. Listing Two shows two wrapper functions for the two use cases, which call the recursive algorithm, and make the use cases more explicit, simplifying and clarifying usage.
Acceleration
To accelerate the Parallel Merge Sort algorithm, let’s follow the obvious approach that has been used in just about every part of this series — the hybrid algorithm with a large enough parallel work quanta. The hybrid approach should accelerate divide-and-conquer by not letting recursion go all the way down to a single element. Terminating recursion early also ensures that the minimum parallel work quanta (sub-array size) is large enough to ensure that task switching overhead stays negligible. Of course, terminating recursion early reduces the amount of total parallelism available. However, the number of cores in current processors is small enough relative to array sizes, ensuring that all cores will be utilized.
Listing Three shows the hybrid algorithm, which uses Insertion Sort to terminate recursion for any sub-array of 48 elements or less. STL stable_sort can also be used, but runs slightly slower. Thus, for any sub-array of 48 or fewer elements, a sequential sorting algorithm is used instead of continuing divide-and-conquer recursion and without using further parallelism. The two “directions” are handled by sorting the src sub-array, and then copying the result to the dst only if the srcToDst is true.
Merge Sort can easily be made stable by using a stable merge. However, when terminating recursion early, care must be taken to use a stable sort, such an Insertion Sort or STL stable_sort. If stability is not important, then a potentially faster sort could be used for recursion termination, such as STL sort.
Figure 4 and Table 2 show performance measurements, with X-axis being array size and Y-axis being seconds to sort.


The hybrid approach accelerated Parallel Merge Sort by over 2X for all array sizes. The resulting algorithm is as much as 7X faster than STL stable_sort, running on a quad-core processor. It’s also faster than STL stable_sort for all array sizes. STL stable_sort is more efficient, in terms of elements/second/core, for array sizes less than 100K elements. At array sizes above 100K elements the Parallel Merge Sort is more efficient.
Simplification
Listing Four shows a slightly simplified implementation that is void of copying in the second termination condition. To avoid the copy, the termination condition continues recursion until the srcToDst “direction” ends up set to false, which requires no copy. In other words, we traded-off one more recursion level in some cases for no copy (and are letting the merge perform the copy). Benchmarks show this to be an even trade, in which case, the simplicity of implementation wins.
Prediction versus Measurement
Parallel Merge algorithm memory bandwidth performance was measured at 7.1 GB/sec for reading and writing. Parallel Merge Sort algorithm is a recursive divide-and-conquer, where the recursion tree has the depth of lgN with each level of the recursion tree being N wide. At each level, N elements are output from merge operations. At the top level, 2 sub-arrays of N/2 size are merged to produce N elements. At the next level, 4 sub-arrays of N/4 size are merged in pairs to produce 2 sub-arrays of N/2 size, and so on; as shown in Figures 2 and 3.
For an array of 1 million, lg(N)=lg(1M)=20. The recursion tree is 20 levels tall, with each level processing 1 million elements at 7.1 GB/sec — 7.1 GB/sec for reading and writing 32-bit elements implies a bandwidth of 7.1 GB/4 bytes=1.8 GigaElements/sec, which translates to a merge output rate of 900 MegaElements/sec. Thus, Parallel Merge Sort should perform at 900 MegaElements/sec/20 levels=45 MegaElements/sec, if the overall performance is dominated by performance of Parallel Merge.
Our measurements are about 50 MegaElements/sec, however, for sorting arrays of 1 million elements. The difference is attributed to fewer levels of recursion, due to early recursion termination for sub-arrays of 48 or fewer elements. lg(48) is in between 5 and 6. Thus, the number of levels is about (20-5)=15. Therefore, Parallel Merge Sort performance should be 900 MegaElements/15=60 MegaElements/sec. Predictions are correlating well with measurements, showing that the Parallel Merge Sort performance is dominated and limited by the performance of Parallel Merge, which is in turn limited by system memory bandwidth.
Conclusion
The Parallel Merge Sort algorithm was built using Parallel Merge, providing a high degree of parallelism,Θ(n/lg2n). The algorithm is generic, by using templates, which allows it to operate on any data type that can use a comparison operator. It’s also stable through the use of a stable sort algorithm as the recursion base case, such as Insertion Sort or STL stable_sort. Base case not only optimized performance by keeping recursion overhead minimal, but also by providing a sufficiently large parallel work quanta to keep parallel task switching overhead minimized. This technique improved performance by about 2X, resulting in a 7X speedup over STL stable_sort on a quad-core processor, peaking at 50 MegaElements/sec.
The Parallel Merge Sort algorithm is not purely in-place, since an extra array is required of the same size as the input array. However, the implementation is capable of two usages: one with source array and destination array, the other with a source/destination array and an auxiliary/intermediate array. In both cases, an additional array to the source array is required. But in the second usage, the result is placed in the source array, resulting in a “pseudo in-place” usage. Of course, one could hide the auxiliary array usage from the user, by allocating this array internally whenever enough memory is available (as STL does). Both of these usages we accomplished by utilizing a core recursive algorithm that swapped source and destination arrays at each level of recursion. This implementation was simplified by terminating recursion at the level that used the source array as the source, which eliminated code for copying while providing equivalent performance.
Performance of the Parallel Merge Sort was shown to be dominated by the performance of Parallel Merge, which is limited by system memory bandwidth.
References
[1] T.H. Cormen, C.E. Leiserson, R.L. Rivest, and C. Stein, Introduction to AlgorithmsIntroduction to Algorithms, Third edition, MIT Press, Sept. 2009, pp. 802-804.

One thought on “Parallel Merge Sort”