This blog is a repost of an article I wrote in Dr. Dobb’s Journal in November of 2009, since Dr. Dobb’s Journal has ceased operation and its website has broken since then. The algorithm developed is a novel In-Place Radix Sort, which sorts in Linear Time. The article is still available through the amazing web archival of the Wayback machine, as provided below:
V.J. Duvanenko, “Algorithm Improvement through Performance Measurement: Part 3. In-Place Hybrid N-bit-Radix Sort”, Nov. 3, 2009
(broken site) http://www.drdobbs.com/architecture-and-design/algorithm-improvement-through-performanc/221600153
The latest implementations in C++ are available in https://github.com/DragonSpit/ParallelAlgorithms – see RadixSortMSD.cpp and RadixSortMsdParallel.cpp, along with usage in RadixSortMsdBenchmark.cpp. Implementations in C# are also available with more data types supported in https://github.com/DragonSpit/HPCsharp.
The In-place Hybrid Binary-Radix Sort I presented in Algorithm Improvement through Performance Measurement: Part 2 sorted arrays of numbers (8, 16, 32 and 64-bit, signed and unsigned) in linear time. The algorithm was shown to outperform the STL sort, but not the Radix-Sort that’s part of Intel’s Integrated Performance Primitives (IPP) library. However, it offered the ability to perform sorting without using extra storage (“in-place”), whereas Intel’s IPP Radix-Sort requires additional storage of equal size to the input array.
The In-place Hybrid Binary-Radix Sort algorithm sorted based of the most-significant-bit first, splitting the array into two bins (0’s and 1’s bin), in-place, and then recursively sorted each of these bins, splitting them into 0’s and 1’s bins, continuing until all bits have been used for sorting. To reduce the overhead of recursion, when the bins were below a certain size, Insertion Sort was used, which boosted the overall performance over a purely Binary-Radix Sort.
Intel’s IPP Radix-Sort algorithm was significantly faster than In-place Hybrid Binary-Radix Sort: 20X for 8-bit, 8X for 16-bit, and 3X for 32-bit unsigned integers, but at the price of 2X the storage. It would be beneficial to develop a Radix Sort implementation that was in-place. That is the focus of this article.
Radix-Sort
Radix Sort does not compare array elements to each other, but instead sorts based on the digits of each array element. It can either sort starting with the most-significant-digit (MSD) or the least-significant-digit (LSD). In the MSD case, the algorithm starts by sorting all array elements into bins based on the MSD. For example, for decimal-radix the array elements would be split into 10 bins based on the MSD. If an element’s MSD was a 0, then it would be placed into bin 0. If an element’s MSD was a 1, then it would be placed into bin 1, and so on. Each bin could then be copied back to the original array, starting with bin 0, then bin1 and so on. Each bin would then be split into sub-bins based on the next digit and so on, until all digits have been used for sorting.
Figure 1 illustrates the concept of splitting the array into bins and then those bins into sub-bins, and so on recursively. At the top level the original array is shown. At the next level down in the tree, the original array is split into bins, up to N-radix of them, based on the first digit. For example, if 256-radix (8-bits) was used, then the up to 256 bins would be created. At the next level, each of these bins is split further into sub-bins, based on the next digit. Once again, up to 256 sub-bins are created if 256-radix is used. Thus, at this level it is possible to have up to 256*256 = 64K sub-bins. This process repeats at the next level using the next digit and so on, until all of the bits within the element have been used for sorting.

For example, for an array made of 16-bit numbers, and using 256-radix sorting starting with the most-significant-digit, the first level would be created by taking the upper 8-bits of each element, looking at that value and placing the element into the bin based on that value. Since there are 256 possible values for 8-bits, then up to 256 bins would be created. Then the next 8-bits of each element are used to break the 256 bins further into 256 sub-bins. For 16-bit numbers, there would be only two levels of bins and sub-bins – i.e., 256*256 = 64K bins at the bottom level. Then a method is needed to collect these bins in the right order.
ff0016 000116 028016 003016 500016 020116
To sort the above array of hex 16-bit unsigned numbers the following steps would be performed:
- The first level is based on the most-significant 8-bits of each element of the array:
- ff0016 would be placed in bin ff16 (bin 256 in decimal),
- 000116 and 003016 would be placed in bin 0,
- 028016 and 020116 would be placed in bin 2,
- 500016 would be placed in bin 5016 (bin 80 in decimal),
- The rest of the 256 bins would not have any elements in them. The first level is done.
- The second level is based on the next 8-bits of each element of the array:
- Bin ff16 does not need to be sorted any further since it has only a single element in it,
- Bin 0 has two elements and is divided into two bins: bin 1 and bin 3016 (48 decimal),
- Bin 2 has two elements and is divided into two bins: bin 8016 (128 decimal) and bin 1,
- Bin 5016 does not need to be sorted any further,
- The second level is done.
- The elements are collected in the order of recursion starting with the lowest number bin on the first level and the second level and progressing to the highest bin on the first and second levels.
The In-place Radix-Sort Concept
The main ideas of in-place Radix-Sort are:
- A pass is performed over the input array to determine how many elements are in each bin – the size of each bin.
- Since the size of each bin has been determined, the starting index within the input array for each bin can be computed.
- Take the first element within the input array and figure out which bin it should move to based on its MSD. Swap it with the element that is at the start of that bin. Grow the size of that bin.
- Examine the new element that was swapped into the first element location. Figure out which bin it should move to. Swap it with the element in that bin. If that bin turns out to be the first bin, then keep the element there and grow the first bin, then process the next element in the array.
- If this next element is inside the next bin, then step over this next bin. If this bin butts against another bin, then skip it too, until an element is found that does not belong to any bin yet.
- Continue in such a manner until all elements within the input array have been placed in their bins.
- Once processing by MSD has been done, call the Radix-Sort itself recursively for each of the bins that has two or more elements in it and sort based on the next digit. Continue recursion until all digits have been used to sort with.
Listing 1 shows an initial in-place 256-radix implementation for arrays of 32-bit unsigned numbers.
// Listing 1
template< class _Type >
inline void _RadixSort_initialUnsigned_Radix256_2( _Type* a, long last, _Type bitMask, unsigned long shiftRightAmount )
{
const unsigned long numberOfBins = 256; // 256-radix (Bins 0 - 255)
unsigned long count[ numberOfBins ];
for( unsigned long i = 0; i < numberOfBins; i++ )
count[ i ] = 0;
for ( long _current = 0; _current <= last; _current++ ) // Scan array. Count number of times each value appears
{
_Type digit = ( a[ _current ] & bitMask ) >> shiftRightAmount; // extract digit sorting is based on
count[ digit ]++;
}
long startOfBin[ numberOfBins ], endOfBin[ numberOfBins ], nextBin;
startOfBin[ 0 ] = endOfBin[ 0 ] = nextBin = 0;
for( unsigned long i = 1; i < numberOfBins; i++ )
startOfBin[ i ] = endOfBin[ i ] = startOfBin[ i - 1 ] + count[ i - 1 ];
for ( long _current = 0; _current <= last; ) // Move elements from original array into bins based on digit value
{
_Type digit = ( a[ _current ] & bitMask ) >> shiftRightAmount; // extract the digit we are sorting based on
if ( endOfBin[ digit ] != _current )
{
_swap( a[ _current ], a[ endOfBin[ digit ]] );
endOfBin[ digit ]++;
}
else {
endOfBin[ digit ]++; // leave the element at its location and grow the bin
_current++; // advance the current pointer to the next element
while( _current >= startOfBin[ nextBin ] && nextBin < numberOfBins ) nextBin++;
while( endOfBin[ nextBin - 1 ] == startOfBin[ nextBin ] && nextBin < numberOfBins )
nextBin++;
if ( _current < endOfBin[ nextBin - 1 ] )
_current = endOfBin[ nextBin - 1 ];
}
}
bitMask >>= 8;
shiftRightAmount -= 8;
if ( bitMask != 0 ) // end recursion when all the bits have been processes
{
for( unsigned long i = 0; i < numberOfBins; i++ )
if (( endOfBin[ i ] - startOfBin[ i ] ) >= 2 )
_RadixSort_initialUnsigned_Radix256_2( &a;[ startOfBin[ i ]], endOfBin[ i ] - 1 - startOfBin[ i ], bitMask, shiftRightAmount );
}
}
// Listing 1
inline void RadixSortInPlace_initialUnsigned_Radix256( unsigned long* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
unsigned long bitMask = 0xFF000000; // bitMask controls how many bits we process at a time
unsigned long shiftRightAmount = 24;
_RadixSort_initialUnsigned_Radix256_2( a, a_size - 1, bitMask, shiftRightAmount );
}
This algorithm follows the recursive method above. A detailed explanation of the inner workings of this algorithm is provided below.
Initial Implementation: The Details
The initial implementation processes 8-bits of each array element at a time, which makes it a 256-radix algorithm. It uses the most-significant 8-bits during the first level of recursion, and then moves to the next 8-bits. Thus, for an array of 16-bit elements, two levels of recursion will be used. For an array of 32-bit elements, four levels of recursion will be used. The bitmask is set to select these most-significant 8-bits, and the shiftRightAmount will also be used to extract the particular 8-bits from each element.
A template function _RadixSort_initialUnsigned_Radix256() is then called, which will be generalized to handle 8, 16, 32 and 64-bit unsigned data types. This function allocates the count array of radix size (256 elements in this case), and initializes each of the counts to zero (in the first for loop). In the second for loop the array that was passed into the function is scanned from beginning to end. For each element the digit that we will be sorting based on is extracted (e.g., the upper 8-bit of each element).
This value (digit) is used as an index into the count array and that particular count is incremented. In other words, this for loop counts how many elements in the array have the most-significant-digit (MSD) equal to a zero, in which case count[0] is incremented. If the digit is a one, then count[1] is incremented, and so on for all other digits up to the digit value of 255, where count[255] is incremented. After the for loop, the count array will hold a count of occurrence of each digit value. From this pass over the array the size of each bin has been determined. This pass is very similar to a histogram in image and video processing domain, where the occurrence of each value of red, green, and blue color component is determined and shown on a graph.
In the third for loop the starting location for each bin is determined, using the count array. Bin 0 starts at location (offset) zero and will hold count[0] elements. Bin 1 will start right after the last element of bin 0 — i.e., at location (offset) of zero plus count[0]. Bin 2 will start at bin 1 starting point plus count[1], and so on for the rest of the bins. Keep in mind that if a bin has zero elements, then it will have a starting point starting point. However, the next bin will have the same starting point as well. The ending point for each bin (marked by endOfBin[] array) is kept track of as each bin is grown in size, when elements are added to it. Initially these ending points (endOfBin[] array) are set to the same value as the starting point of each bin, indicating that each array has zero elements in it. The difference between the starting and ending points (e.g., endOfBin[0] — startOfBin[0] ) indicates how many elements are currently in that bin.
The fourth for loop performs sorting based on the current digit. The loop iterates through all elements within the array given to the function. For each element in the array, the first step is to extract the digit that is used to sort with by masking and shifting. The _current location within the array is where the current array element is being processed. This location starts out being at the same location as startOfBin[0] and endOfBin[0]. Next, the if statement compares the _current location with the endOfBin[digit], where the _current element should be moved to based on the extracted digit. If the _current element belongs to a bin with endOfBin[digit] that is different from _current, then the _current location within the array does not need to be advanced. The _current element is moved to the bin it belongs to and the element that was at that location is moved to the _current location (the swap operation). That bin is also grown. This iteration of the loop is done. The _current location within the array holds a new element that was swapped in. This new element will be processed in the next loop iteration.
The fourth for loop also has an else portion of the if statement, where processing occurs when the element at the current location belongs in the current Bin. In this case, the element does not need to be moved, and the current Bin is grown (by incrementing its endOfBin). The current location (_current) is incremented, at which point several conditions can occur. The _current location index could end up inside the next bin, which is the condition the first while loop looks for. This situation is illustrated in the diagram below:

Bin 0 starts with a0 which it contains, and the startOfBin[0] points to (left arrow with a circular tail). The value at a1 is not part of bin 0 yet, and is the value being analyzed. The endOfBin[0] pointer is set to the one beyond the end of bin 0, pointing to the next potential candidate. The _current pointer is located at a1 as well, which is the value the for loop is processing. Since the _current element has the upper 8-bit of value equal to zero (in bold) this element belongs in bin 0. No swapping or moving is needed. Bin 0 needs to be grown to include a1 element, and the algorithm does this by advancing the endOfBin[0] for bin 0. The resulting situation is illustrated on the next line of the diagram.
In this case, bin 0 has been filled — all of the elements that belong to bin 0 have been found and moved to bin 0. Now, bin 0 butts against bin 1 without any gaps. The _current pointer is selecting element a2 which belongs to bin 1. Thus, bin 1 needs to be skipped. This is the situation that the second while loop processes. In this case, several bins butt against each other with no gaps in between. The second while loop skips all of the bins until a gap is found with an element that does not yet belong to any of the bins, or all of the bins have been processed (filled). At this point the _current pointer will either point to the next unprocessed element in between bins or past the end of array — past _last (and the main loop will exit):

Another scenario that can occur is illustrated in the diagram above. In this case, bin 0 has just been grown by adding a1 element, and current pointer was moved to a2 element. However, bin 1 contains zero elements in it (startofBin[1] and endOfBin[1] point to a2). This is the case that the first while loop takes care of. In this case, nextBin is advanced. NextBin keeps track on which bin is the next bin after the _current pointer. In the case above, since the _current pointer was at the same location as endOfBin[0] — i.e., the current bin was bin 0 — the nextBin value was 1 (to indicated that bin 1 was next). By using the nextBin value, the while loop is able to check whether the _current pointer has reached the start of the next bin, which then needs to be skipped. This is the condition shown in the diagram above — _current pointer is equal to startOfBin[1], and thus bin 1 needs to be skipped, which is done by incrementing nextBin. A while loop is used in this case, instead of an if statement, because several bins in a row could have zero elements in then and all of them would start at a2 element. This while loop will skip all of these zero size bins. Performance measurements of this initial implementation are shown in Table 1, along with STL sort, Intel’s IPP Radix Sort, Intel’s sort, Hybrid Binary-Radix Sort, and Insertion Sort:


These measurements show the initial 256-Radix Sort implementation lagging in performance comparing to all other sorting algorithms, except Insertion Sort for large input data sets. Note that STL sort and Hybrid Binary-Radix Sort perform substantially better than other algorithms for small input data sets because they are hybrid algorithms and utilize Insertion Sort for small data sets [1].
The same correctness tests were performed on every algorithm described, as was performed in [1]. The same performance tests were performed as in Algorithm Improvement through Performance Measurement: Part 2.
Hybrid
It is simple to convert the initial 256-Radix Sort implementation to a Hybrid implementation by letting Insertion Sort handle any recursion for a small number of elements. This strategy was used successfully by STL sort and by Hybrid Binary-Radix Sort in (see Algorithm Improvement through Performance Measurement: Part 2). In the case of Hybrid Binary-Radix Sort the performance was improved by about 30%. However, 256-Radix Sort has a substantially larger overhead than Hybrid Binary-Radix Sort or Insertion Sort, which shows up in measurements shown in Table 1 and Graph 1, where Insertion Sort is significantly faster for input data set under 1K elements. Table 2 and Graph 2 compare non-Hybrid and Hybrid implementations of 256-Radix Sort.

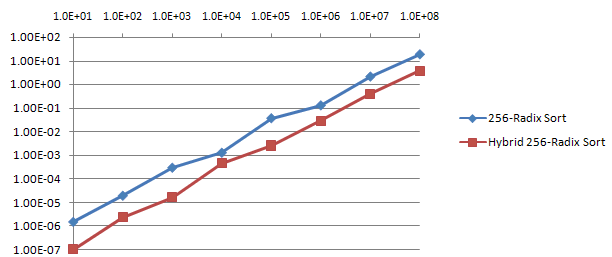
Listing 2 shows the Hybrid 256-Radix Sort implementation. Note that the same value of 32 that was used in [1] for Hybrid Binary-Radix Sort is used as a threshold to decide whether to call Insertion Sort or not. Also, the decision is made immediately before calling Hybrid 256-Radix Sort, to avoid the overhead of executing the Hybrid 256-Radix Sort even once when the array size is smaller than the threshold.
// Listing 2
template< class _Type >
inline void insertionSortSimilarToSTLnoSelfAssignment( _Type* a, unsigned long a_size )
{
for ( unsigned long i = 1; i < a_size; i++ )
{
if ( a[ i ] < a[ i - 1 ] ) // no need to do (j > 0) compare for the first iteration
{
_Type currentElement = a[ i ];
a[ i ] = a[ i - 1 ];
unsigned long j;
for ( j = i - 1; j > 0 && currentElement < a[ j - 1 ]; j-- )
{
a[ j ] = a[ j - 1 ];
}
a[ j ] = currentElement; // always necessary work/write
}
// Perform no work at all if the first comparison fails - i.e. never assign an element to itself!
}
}
template< class _Type >
inline void _RadixSort_HybridUnsigned_Radix256( _Type* a, long last, _Type bitMask, unsigned long shiftRightAmount )
{
const unsigned long numberOfBins = 256; // 256-radix (Bins 0 - 255)
unsigned long count[ numberOfBins ];
for( unsigned long i = 0; i < numberOfBins; i++ )
count[ i ] = 0;
for ( long _current = 0; _current <= last; _current++ ) // Scan the array and count the number of times each value appears
{
_Type digit = ( a[ _current ] & bitMask ) >> shiftRightAmount; // extract the digit sorting is based on
count[ digit ]++;
}
long startOfBin[ numberOfBins ], endOfBin[ numberOfBins ], nextBin;
startOfBin[ 0 ] = endOfBin[ 0 ] = nextBin = 0;
for( unsigned long i = 1; i < numberOfBins; i++ )
startOfBin[ i ] = endOfBin[ i ] = startOfBin[ i - 1 ] + count[ i - 1 ];
for ( long _current = 0; _current <= last; ) // Move elements from the original array into the bins based on digit value
{
_Type digit = ( a[ _current ] & bitMask ) >> shiftRightAmount; // extract the digit we are sorting based on
if ( endOfBin[ digit ] != _current )
{
_swap( a[ _current ], a[ endOfBin[ digit ]] );
endOfBin[ digit ]++;
}
else {
endOfBin[ digit ]++; // leave the element at its location and grow the bin
_current++; // advance the current pointer to the next element
while( _current >= startOfBin[ nextBin ] && nextBin < numberOfBins )
nextBin++;
while( endOfBin[ nextBin - 1 ] == startOfBin[ nextBin ] && nextBin < numberOfBins )
nextBin++;
if ( _current < endOfBin[ nextBin - 1 ] )
_current = endOfBin[ nextBin - 1 ];
}
}
bitMask >>= 8;
shiftRightAmount -= 8;
if ( bitMask != 0 ) // end recursion when all the bits have been processes
{
for( unsigned long i = 0; i < numberOfBins; i++ )
if (( endOfBin[ i ] - startOfBin[ i ] ) >= 32 )
_RadixSort_HybridUnsigned_Radix256( &a;[ startOfBin[ i ]], endOfBin[ i ] - 1 - startOfBin[ i ], bitMask, shiftRightAmount );
else if (( endOfBin[ i ] - startOfBin[ i ] ) >= 2 )
insertionSortSimilarToSTLnoSelfAssignment( &a;[ startOfBin[ i ]], endOfBin[ i ] - startOfBin[ i ]);
}
}
// Listing 2
inline void RadixSortInPlace_HybridUnsigned_Radix256( unsigned long* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
unsigned long bitMask = 0xFF000000; // bitMask controls how many bits we process at a time
unsigned long shiftRightAmount = 24;
if ( a_size >= 32 )
_RadixSort_HybridUnsigned_Radix256(a, a_size - 1, bitMask, shiftRightAmount );
else
insertionSortSimilarToSTLnoSelfAssignment( a, a_size );
}
Inside the Hybrid 256-Radix Sort template function (which recurses) the recursion threshold check is done at the end of the function and not at the beginning because this is more efficient by several percent. Otherwise, if the check whether to call Insertion Sort or not is done at the top of the template function, then 256-Radix Sort would be called only then to decide that Insertion Sort should have been called, adding an unnecessary function call overhead before every call to Insertion Sort.
These measurements show that a Hybrid 256-Radix Sort using Insertion Sort substantially improves the performance of the algorithm. This is due to Insertion Sort having much lower overhead for small input data sets (see Table 1 and Graph 1).
Improvements
Listing 3 shows an improved Hybrid Radix Sort implementation. This implementation improves not only performance but extends the algorithm to handle unsigned numbers from 8-bit to 64-bit. Also, the radix is no longer fixed at 256 (8-bits), but can be any power-of-two – i.e., any number of bits.
// Listing 3
template< class _Type, unsigned long PowerOfTwoRadix, unsigned long Log2ofPowerOfTwoRadix, long Threshold >
inline void _RadixSort_Unsigned_PowerOf2Radix_1( _Type* a, long last, _Type bitMask, unsigned long shiftRightAmount )
{
const unsigned long numberOfBins = PowerOfTwoRadix;
unsigned long count[ numberOfBins ];
for( unsigned long i = 0; i < numberOfBins; i++ )
count[ i ] = 0;
for ( long _current = 0; _current <= last; _current++ ) // Scan the array and count the number of times each value appears
{
unsigned long digit = (unsigned long)(( a[ _current ] & bitMask ) >> shiftRightAmount ); // extract the digit we are sorting based on
count[ digit ]++;
}
long startOfBin[ numberOfBins ], endOfBin[ numberOfBins ], nextBin;
startOfBin[ 0 ] = endOfBin[ 0 ] = nextBin = 0;
for( unsigned long i = 1; i < numberOfBins; i++ )
startOfBin[ i ] = endOfBin[ i ] = startOfBin[ i - 1 ] + count[ i - 1 ];
for ( long _current = 0; _current <= last; )
{
unsigned long digit;
_Type tmp = a[ _current ]; // get the compiler to recognize that a register can be used for the loop instead of a[_current] memory location
while ( true ) {
digit = (unsigned long)(( tmp & bitMask ) >> shiftRightAmount ); // extract the digit we are sorting based on
if ( endOfBin[ digit ] == _current )
break;
_swap( tmp, a[ endOfBin[ digit ] ] );
endOfBin[ digit ]++;
}
a[ _current ] = tmp;
endOfBin[ digit ]++; // leave the element at its location and grow the bin
_current++; // advance the current pointer to the next element
while( _current >= startOfBin[ nextBin ] && nextBin < numberOfBins )
nextBin++;
while( endOfBin[ nextBin - 1 ] == startOfBin[ nextBin ] && nextBin < numberOfBins )
nextBin++;
if ( _current < endOfBin[ nextBin - 1 ] )
_current = endOfBin[ nextBin - 1 ];
}
bitMask >>= Log2ofPowerOfTwoRadix;
if ( bitMask != 0 ) // end recursion when all the bits have been processes
{
if ( shiftRightAmount >= Log2ofPowerOfTwoRadix ) shiftRightAmount -= Log2ofPowerOfTwoRadix;
else shiftRightAmount = 0;
for( unsigned long i = 0; i < numberOfBins; i++ )
{
long numberOfElements = endOfBin[ i ] - startOfBin[ i ];
if ( numberOfElements >= Threshold ) // endOfBin actually points to one beyond the bin
_RadixSort_Unsigned_PowerOf2Radix_1< _Type, PowerOfTwoRadix, Log2ofPowerOfTwoRadix, Threshold >( &a;[ startOfBin[ i ]], numberOfElements - 1, bitMask, shiftRightAmount );
else if ( numberOfElements >= 2 )
insertionSortSimilarToSTLnoSelfAssignment( &a;[ startOfBin[ i ]], numberOfElements );
}
}
}
The main performance improvement is based on the realization that swapping of elements happens with the highest probability. In the case of 256-Radix, the bin where the _current pointer is located is only one out of 256 bins, and thus the chance of finding a number that goes into that bin are one of 256. The first while loop inside the main for sorting loop takes care of this condition (elements not belonging to the _current bin) and stays in it while this is true (probability of 255/256 = 99.6%). The use of tmp variable gives the compiler a chance to use a CPU register for swapping instead of the _current array memory location.
The threshold value that determines if the array size is small enough to use Insertion Sort was set to 32. This value was borrowed from the Hybrid Binary-Radix Sort where it was experimentally determined to be best. Table 3 shows results of experiments for Radix-Sort of arrays of 32-bit elements, to determine the best setting for the threshold.

In the top portion of the table the threshold is varied from 8 elements to 512 elements. In the bottom portion of the table the ratio of Radix-Sort to IPP Radix-Sort is computed. From these measurements it is evident that the threshold values of 32 and smaller perform inferior, as well as values of 256 and larger. Value of about 100 seems a good choice.
Table 4 and Graph 4 compare In-place Hybrid Radix-Sort (using 256-radix) with Intel’s IPP Radix-Sort (not in-place) and STL sort, for 32-bit unsigned numbers.
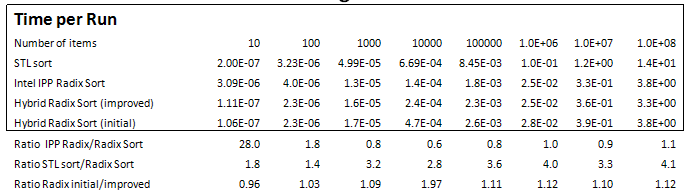
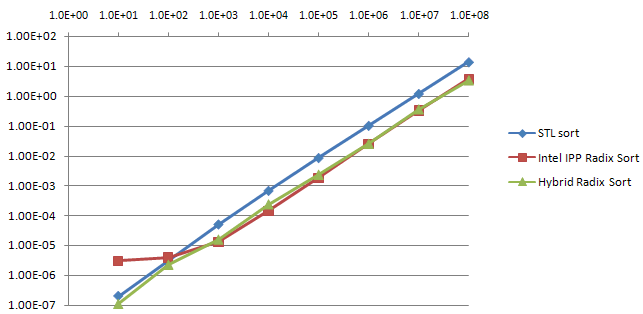
They show the two Radix algorithms have comparable performance for large arrays, for mid-size arrays IPP outperforms, and for small arrays Hybrid Radix outperforms. These measurements also show STL sort lagging in performance for all array sizes. Table 4 also quantifies, in the bottom row, the impact of the speed-up improvements, which improved performance for all array sizes except the smallest.
Radix support has been extended to an arbitrary power-of-two-radix; i.e., an arbitrary number of bits at a time (up to 32-bits). This radix value needed to be passed to the function, as a true constant, since the count[] array size is allocated based on the radix. Template functions allow constants to be passed to the function, but do not support default values for these constants [2]. This fact about C++ is disappointing, but can be hidden from the user inside a library. Listing 3 shows the use of overloaded sorting functions for each data type with a core template function that is type independent. Also, note that not only the radix and data type are passed to the template function, but also the threshold value of when to switch to Insertion Sort.
Handling arbitrary power-of-two-radix (i.e., any number of bits) also includes support for the case where the number of bits of the array elements does not evenly divide by the number of bits in the radix; e.g., 32-bit elements and 11-bit-radix. In this case, three passes would be performed: 11-bit, 11-bit and 10-bit. Actually, the last pass would still be an 11-bit pass, but the mask would be only 10-bits. Thus the count[] array would be allocated with 2048 elements, but there would only be 1024 possible “digits”, leaving half of the bins empty, and still functioning properly.
From Table 5, which compares non-Hybrid N-bit-Radix Sort variations, it seems hopeful that 16-Radix Sort (4-bit) or 64-Radix (6-bit) could outperform 256-Radix (8-bit) as a Hybrid algorithm. However, this did not prove fruitful even when varying the threshold between 8 and 512, most likely because 16-Radix required eight passes and 64-Radix required six passed, compared to only four passed for 256-Radix, for 32-bit unsigned array elements.

2048-Radix (11-bit) did not succeed, even though it used only 3 passes, most likely because of its poor initial performance (as seen in Table 5). Using the Hybrid algorithm in this case improved performance, but not enough to be superior to 256-Radix (8-bit) version. The conclusion is 256-Radix (8-bit) Hybrid algorithm is the best performing combination over the entire range of array sizes for 32-bit unsigned array elements.
Table 6 and Graph 6 show measurements of various algorithms when sorting 64-bit unsigned integers. Intel did not implement sorting for 64-bit unsigned integers.
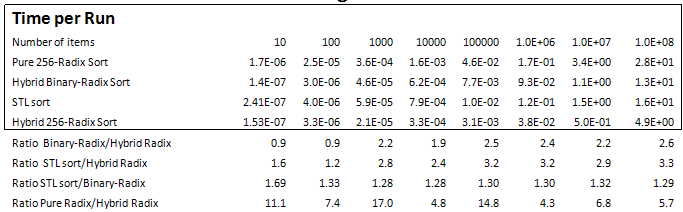

These measurements show that Hybrid 256-Radix (8-bit) Sort outperforms STL sort and Hybrid Binary-Radix Sort from [1]. All three algorithms being compared are in-place. When comparing a pure Radix implementation with the Hybrid Radix, performance gains are measured for all array sizes, and of similar magnitude as gains for 32-bit unsigned (in Table 2).
Table 7 and Graph 7 show performance measurements of several sorting algorithms, some in-place and other not, for arrays of 16-bit unsigned integers. Intel IPP Radix Sort outperforms all others in all but the smallest array size (where Insertion Sort is used by some). The best performing threshold value for the Hybrid 256-Radix Sort was found to be 64, which is used in Table 7. Hybrid 256-Radix Sort lags IPP Radix Sort in performance by nearly 2X, and provides a trade-off between memory usage (being in-place and using half the memory). Intel Sort, STL sort and Hybrid-Binary Sort from [1], all performed nearly equally, lagging in performance.


Other potential radix values were tested, such as 2-bit, 4-bit, and 6-bit, with various threshold settings, but none were faster than 256-Radix (8-bit). Table 7 and Graph 7 also compare a pure 256-Radix implementation to a Hybrid 256-Radix, where at 100K size array and larger the hybrid version offers no performance improvement. The reason is that at 10K elements, 256-Radix divides the array into 256 bins in the first level of recursion, each array being about 39 elements. This array size is small enough to trigger the use of Insertion Sort, and results in faster performance for the Hybrid 256-Radix Sort for array sizes of 10K elements and smaller. However, at 100K elements division into 256 bins results in each bin holding 390 elements, which is above the threshold, resulting in not using Insertion Sort in the second/last recursion level, leading to no performance gain for the Hybrid implementation. In other words, at 10K elements and below the algorithm is a Hybrid 256-Radix Sort (leveraging Insertion Sort), but at 100K and above the algorithm is a pure 256-Radix Sort (not leveraging Insertion Sort). This behavior was verified by instrumenting the algorithm to check whether Insertion Sort was called for arrays larger than 100K elements in size, and it was not (but was called for smaller array sizes).
Table 8 and Graph 8 show measurements of variety of algorithms.


Intel IPP Radix Sort and Counting Sort substantially outperform all others except for the smallest array size, and track in performance closely, with Counting Sort slightly faster for larger array sizes. Counting Sort will be discussed in more detail in a later section. STL and Hybrid Binary-Radix Sort from Algorithm Improvement through Performance Measurement: Part 2 are close in performance and lag all others. Hybrid 256-Radix Sort and Pure 256-Radix Sort track in performance, because for 8-bit elements only the first level of recursion is executed and Insertion Sort is never called. Trial of Hybrid 16-Radix Sort (4-bit) resulted in lower performance. Hybrid 256-Radix and Pure 256-Radix Sort outperform STL sort and Binary-Radix Sort, but lag IPP Radix Sort and Counting Sort.
An optimization that did not yield performance improvement is to combine count[] array and startOfBin[] array into a single array. This optimization reduced stack memory usage of the algorithm, but decreased performance by a few percent due to more complex computation of startOfBin[] values.
Signed
Signed integers use 2’s complement format shown below, with the binary representation on the left and its decimal value on the right:
01111111b 127
01111110b 126
01111101b 125
….
00000001b 1
00000000b 0
11111111b -1
11111110b -2
11111101b -3
…
10000011b -125
10000010b -126
10000001b -127
10000000b -128
Note that the most-significant-bit (MSB) serves as the sign bit. However, its meaning is opposite of what is needed for sorting (see Algorithm Improvement through Performance Measurement: Part 2_ and this bit either needs to be inverted or processed using opposite sense. Listing 4 shows the implementation for signed number, from 8-bit to 64-bit.
// Listing 4
// Treats the first digit specially, but the rest of the digits as unsigned.
template< class _Type, unsigned long PowerOfTwoRadix, unsigned long Log2ofPowerOfTwoRadix, long Threshold >
inline void _RadixSort_Signed_PowerOf2Radix_1( _Type* a, long last, _Type bitMask, unsigned long shiftRightAmount )
{
const unsigned long numberOfBins = PowerOfTwoRadix;
unsigned long count[ numberOfBins ];
for( unsigned long i = 0; i < numberOfBins; i++ )
count[ i ] = 0;
for ( long _current = 0; _current <= last; _current++ ) // Scan the array and count the number of times each value appears
{
unsigned long digit = (unsigned long)logicalRightShift_ru( (_Type)( a[ _current ] & bitMask ),shiftRightAmount ); // extract the digit we are sorting based on
digit ^= ( PowerOfTwoRadix >> 1 );
count[ digit ]++;
}
long startOfBin[ numberOfBins ], endOfBin[ numberOfBins ], nextBin;
startOfBin[ 0 ] = endOfBin[ 0 ] = nextBin = 0;
for( unsigned long i = 1; i < numberOfBins; i++ )
startOfBin[ i ] = endOfBin[ i ] = startOfBin[ i - 1 ] + count[ i - 1 ];
for ( long _current = 0; _current <= last; )
{
unsigned long digit;
_Type tmp = a[ _current ]; // get the compiler to recognize that a register can be used for the loop instead of a[_first] memory location
while ( true )
{
digit = (unsigned long)logicalRightShift_ru( (_Type)( tmp & bitMask ), shiftRightAmount );
// extract the digit we are sorting based on
digit ^= ( PowerOfTwoRadix >> 1 );
if ( endOfBin[ digit ] == _current )
break;
_swap( tmp, a[ endOfBin[ digit ]] );
endOfBin[ digit ]++;
}
a[ _current ] = tmp;
endOfBin[ digit ]++; // leave the element at its location and grow the bin
_current++; // advance the current pointer to the next element
while( _current >= startOfBin[ nextBin ] && nextBin < numberOfBins )
nextBin++;
while( endOfBin[ nextBin - 1 ] == startOfBin[ nextBin ] && nextBin < numberOfBins )
nextBin++;
if ( _current < endOfBin[ nextBin - 1 ] )
_current = endOfBin[ nextBin - 1 ];
}
bitMask = logicalRightShift( bitMask, Log2ofPowerOfTwoRadix );
if ( bitMask != 0 ) // end recursion when all the bits have been processes
{
if ( shiftRightAmount >= Log2ofPowerOfTwoRadix ) shiftRightAmount -= Log2ofPowerOfTwoRadix;
else shiftRightAmount = 0;
for( unsigned long i = 0; i < numberOfBins; i++ )
{
long numberOfElements = endOfBin[ i ] - startOfBin[ i ];
if ( numberOfElements >= Threshold ) // currentOffset actually points to one beyond the bin
_RadixSort_Unsigned_PowerOf2Radix_1< _Type, PowerOfTwoRadix, Log2ofPowerOfTwoRadix, Threshold >( &a;[ startOfBin[ i ]], numberOfElements - 1, bitMask, shiftRightAmount );
else if ( numberOfElements >= 2 )
insertionSortSimilarToSTLnoSelfAssignment( &a;[ startOfBin[ i ]], numberOfElements );
}
}
}
Two special steps are taken to treat signed numbers differently than unsigned, as shown here:
digit = (unsigned long)logicalRightShift_ru( (_Type)( tmp & bitMask ), shiftRightAmount );
digit ^= ( PowerOfTwoRadix >> 1 );
The first step performs a right shift of a signed number as if it was unsigned. The second step inverts the most-significant-bit. The rest of the code is identical to the initial iteration of unsigned implementation, except for another logical right shift of the bitMask. The rest of the recursive iterations are performed using the unsigned algorithm.
In Tables 9 through 12, measurements show a performance degradation of a few percent due to the need to invert the MSB of the first digit. This overhead gets smaller as the element size increases. The rest of the performance characteristics match those of the unsigned implementations. Note that Intel IPP does not implement signed 8-bit or 64-bit integer versions of sorting.

Table 9: Random 8-bit Signed Elements

Table 10: Random 16-bit Signed Elements

Table 11: Random 32-bit Signed Elements

Table 12: Random 64-bit Signed Elements
Counting Sort
Table 8 and Graph 8 introduced the Counting Sort algorithm by comparing its superior performance to others. Listing 5 is an implementation for sorting unsigned 8-bit integers. The algorithm works by creating 256 counters, one for each possible value that an array element can be. These counters are initialized to a count of zero. Then the array is scanned the first time to count how many times each value appears. For example, for the following array:
0, 2, 15, 200, 0, 3, 12, 203, 181, 181, 2, 0, 2, 12, 0, 3, 15
the counts would be count[0]=4, count[1]=0, count[2]=3, count[3]=2, count[12]=2, count[15]=2, count[181]=2, count[200]=1, count[203]=1, and the rest of the count[] array would be zero. The next for loop starts and count[0] and stores the number of zeros into the array as the value that count[0] hold. In the above example, array[0]=0, array[1]=0, array[2]=0, and array[3]=3, since count[0] was equal 4. Since count[1] is zero, then zero values of 1 are stored in the array. Then array[4]=2, array[5]=2, and array[6]=2, since three 2’s were found in the input array. This process continues until the entire count array has been processed. As Table 8 and Graph 8 measurements show this process is very efficient for 8-bit unsigned numbers and outperforms all other algorithms by a wide margin.
Listing 5 also shows a Counting Sort implementation for 16-bit unsigned numbers as well as a Hybrid Counting Sort, which combines the Counting Sort with Insertion Sort. Table 13 and Graph 13 show measurement results of these three implementations along with Insertion Sort.
//Listing 5
inline void CountSortInPlace( unsigned char* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
const unsigned long numberOfCounts = 256;
// one count for each possible value of an 8-bit element (0-255)
unsigned long count[ numberOfCounts ] = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
};
//for( unsigned long i = 0; i < numberOfCounts; i++ ) // initialized all counts to zero, since the array may not contain all values
// count[ i ] = 0;
// !!! It should be possible to use array initialization and remove this overhead!!!
// Scan the array and count the number of times each value appears
for( unsigned long i = 0; i < a_size; i++ )
count[ a[ i ] ]++;
// Fill the array with the number of 0's that were counted, followed by the number of 1's, and then 2's and so on
unsigned long n = 0;
for( unsigned long i = 0; i < numberOfCounts; i++ )
for( unsigned long j = 0; j < count[ i ]; j++, n++ )
a[ n ] = (unsigned char)i;
}
inline void CountSortInPlace( unsigned short* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
const unsigned long numberOfCounts = 65536;
// one count for each possible value of an 16-bit element (0-65535/0xffff)
unsigned long count[ numberOfCounts ];
for( unsigned long i = 0; i < numberOfCounts; i++ ) // initialized all counts to zero, since the array may not contain all values
count[ i ] = 0;
// Scan the array and count the number of times each value appears
for( unsigned long i = 0; i < a_size; i++ )
count[ a[ i ] ]++;
// Fill array with the number of 0's counted, followed by the number of 1's, and then 2's and so on
unsigned long n = 0;
for( unsigned long i = 0; i < numberOfCounts; i++ )
for( unsigned long j = 0; j < count[ i ]; j++, n++ )
a[ n ] = (unsigned short)i;
}

Table 13: Counting sort, 16-bit Unsigned
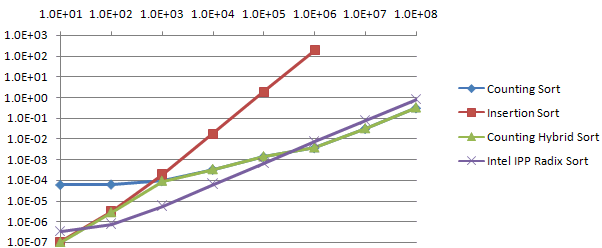
These measurements show that Intel IPP Radix Sort outperforms the Hybrid 256-Radix Sort by about 2X, but lags 16-bit Count Sort by about 2X for large array sizes. For mid-size arrays Intel IPP Radix Sort outperforms all others. It seems that a 3-way Hybrid would produce a superior combination, with Insertion Sort for up to 30-50 element arrays, Intel IPP Radix for 50 to 500K arrays, and 16-bit Counting Sort for all largest array sizes. However, Intel IPP Radix Sort is not in place, forcing the combination to be not in-place. This may still be an effective combination, since only the mid-section would be required to be not-in-place, where the requirement of doubling memory size may not be a concern, as it would be at larger array sizes.
Counting Sort will be explored in more detail in future articles, since its performance needs to be examined closer due to concerns about sustainable superior performance depending of input data statistics. The above measurements show potential.
Aggregate
Listing 6 is a list of overloaded functions that combine to produce a data-type aware slightly generic sorting.
// Copyright(c), Victor J. Duvanenko, 2009
// Hybrid In-place Radix Sort implementations.
#ifndef _HybridInPlaceRadixSort_h
#define _HybridInPlaceRadixSort_h
#include "InsertionSort.h"
#include "RadixInPlaceSort.h"
#include "CountSort.h"
inline void HybridSort( char* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
const long PowerOfTwoRadix = 256;
const long Log2ofPowerOfTwoRadix = 8;
const long Threshold = 64;
char bitMask = (char)0x80; // bitMask controls how many bits are processed at a time
unsigned long shiftRightAmount = 7;
for( unsigned long i = 2; i < PowerOfTwoRadix; ) // if not power-of-two value then it will do up to the largest power-of-two value
{ // that's smaller than the value provided (e.g. radix-10 will do radix-8)
bitMask |= logicalRightShift( bitMask, 1 );
shiftRightAmount -= 1;
i <<= 1;
}
if ( a_size >= Threshold )
_RadixSort_Signed_PowerOf2Radix_1< char, PowerOfTwoRadix, Log2ofPowerOfTwoRadix, Threshold >( a, a_size - 1, bitMask, shiftRightAmount );
else
insertionSortSimilarToSTLnoSelfAssignment( a, a_size );
}
inline void HybridSort( unsigned char* a, unsigned long a_size )
{
if ( a_size > 32 )
CountSortInPlace( a, a_size );
else
insertionSortSimilarToSTLnoSelfAssignment( a, a_size );
}
inline void HybridSort( short* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
const long PowerOfTwoRadix = 256;
const long Log2ofPowerOfTwoRadix = 8;
const long Threshold = 64;
short bitMask = (short)0x8000; // bitMask controls how many bits we process at a time
unsigned long shiftRightAmount = 15;
for( unsigned long i = 2; i < PowerOfTwoRadix; ) // if not power-of-two value then it will do up to the largest power-of-two value
{ // that's smaller than the value provided (e.g. radix-10 will do radix-8)
bitMask |= logicalRightShift( bitMask, 1 );
shiftRightAmount -= 1;
i <<= 1;
}
if ( a_size >= Threshold )
_RadixSort_Signed_PowerOf2Radix_1< short, PowerOfTwoRadix, Log2ofPowerOfTwoRadix, Threshold >( a, a_size - 1, bitMask, shiftRightAmount );
else
insertionSortSimilarToSTLnoSelfAssignment( a, a_size );
}
inline void HybridSort( unsigned short* a, unsigned long a_size, unsigned short* b = NULL )
{
if ( a_size >= 1000000 )
CountSortInPlace( a, a_size );
else {
if ( b == NULL ) // Can't use IPP Radix without the extra array b
{
if ( a_size > 100 )
CountSortInPlace( a, a_size );
else
insertionSortSimilarToSTLnoSelfAssignment( a, a_size );
}
else {
if ( a_size > 100 )
ippsSortRadixAscend_16u_I( reinterpret_cast< Ipp16u * > ( a ), reinterpret_cast< Ipp16u * > ( b ), a_size );
else
insertionSortSimilarToSTLnoSelfAssignment( a, a_size );
}
}
}
inline void HybridSort( long* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
const long PowerOfTwoRadix = 256;
const long Log2ofPowerOfTwoRadix = 8;
const long Threshold = 100;
long bitMask = 0x80000000; // bitMask controls how many bits we process at a time
unsigned long shiftRightAmount = 31;
for( unsigned long i = 2; i < PowerOfTwoRadix; ) // if not power-of-two value then it will do up to the largest power-of-two value
{ // that's smaller than the value provided (e.g. radix-10 will do radix-8)
bitMask |= logicalRightShift( bitMask, 1 );
shiftRightAmount -= 1;
i <<= 1;
}
if ( a_size >= Threshold )
_RadixSort_Signed_PowerOf2Radix_1< long, PowerOfTwoRadix, Log2ofPowerOfTwoRadix, Threshold >( a, a_size - 1, bitMask, shiftRightAmount );
else
insertionSortSimilarToSTLnoSelfAssignment( a, a_size );
}
inline void HybridSort( unsigned long* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
const long PowerOfTwoRadix = 256;
const long Log2ofPowerOfTwoRadix = 8;
const long Threshold = 100;
unsigned long bitMask = 0x80000000; // bitMask controls how many bits we process at a time
unsigned long shiftRightAmount = 31;
for( unsigned long i = 2; i < PowerOfTwoRadix; ) // if not power-of-two value then it will do up to the largest power-of-two value
{ // that's smaller than the value provided (e.g. radix-10 will do radix-8)
bitMask |= ( bitMask >> 1 );
shiftRightAmount -= 1;
i <<= 1;
}
if ( a_size >= Threshold )
_RadixSort_Unsigned_PowerOf2Radix_1< unsigned long, PowerOfTwoRadix, Log2ofPowerOfTwoRadix, Threshold >( a, a_size - 1, bitMask, shiftRightAmount );
else
insertionSortSimilarToSTLnoSelfAssignment( a, a_size );
}
inline void HybridSort( __int64* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
const long PowerOfTwoRadix = 256;
const long Log2ofPowerOfTwoRadix = 8;
const long Threshold = 64;
__int64 bitMask = 0x8000000000000000i64; // bitMask controls how many bits process at a time
unsigned long shiftRightAmount = 63;
for( unsigned long i = 2; i < PowerOfTwoRadix; ) // if not power-of-two value then it will do up to the largest power-of-two value
{ // that's smaller than the value provided (e.g. radix-10 will do radix-8)
bitMask |= logicalRightShift( bitMask, 1 );
shiftRightAmount -= 1;
i <<= 1;
}
if ( a_size >= Threshold )
_RadixSort_Signed_PowerOf2Radix_1< __int64, PowerOfTwoRadix, Log2ofPowerOfTwoRadix, Threshold >( a, a_size - 1, bitMask, shiftRightAmount );
else
insertionSortSimilarToSTLnoSelfAssignment( a, a_size );
}
inline void HybridSort( unsigned __int64* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
const long PowerOfTwoRadix = 256;
const long Log2ofPowerOfTwoRadix = 8;
const long Threshold = 64;
unsigned __int64 bitMask = 0x8000000000000000i64 // bitMask controls how many bits we process at a time
unsigned long shiftRightAmount = 63;
for( unsigned long i = 2; i < PowerOfTwoRadix; ) // if not power-of-two value then it will do up to the largest power-of-two value
{ // that's smaller than the value provided (e.g. radix-10 will do radix-8)
bitMask |= bitMask >> 1;
shiftRightAmount -= 1;
i <<= 1;
}
if ( a_size >= Threshold )
_RadixSort_Unsigned_PowerOf2Radix_1< unsigned __int64, PowerOfTwoRadix, Log2ofPowerOfTwoRadix, Threshold >( a, a_size - 1, bitMask, shiftRightAmount );
else
insertionSortSimilarToSTLnoSelfAssignment( a, a_size );
}
#endif // _HybridInPlaceRadixSort_h
The user calls the sort() function passing it an array of 8-bit through 64-bit unsigned or signed integers. The appropriate function for the data-type gets invoked and sorting algorithms optimized for that data-type and array size are executed, resulting in the optimized overall performance. The sorting algorithms used underneath when appropriate are Counting Sort, Insertion Sort, Intel IPP Radix Sort, and 256-Radix Sort. Note the optional additional optional function argument of a pointer to a memory buffer. If this parameter is NULL then Intel IPP Radix Sort is not used for 16-bit integer sorting of mid-size arrays.
Conclusion
In-place Hybrid Binary-Radix Sort algorithm was developed in [1] for arrays of 8-bit to 64-bit unsigned and signed integers, competitive in performance to STL sort, but inferior to Intel’s IPP Radix Sort. That effort was extended in this paper by first developing an in-place MSD pure N-bit-Radix Sorting algorithm, which was slightly slower than STL sort and much slower than Intel’s IPP Radix Sort.
Binary-Radix Sort was shown in Algorithm Improvement through Performance Measurement: Part 2 to benefit from being combined with Insertion Sort to form a Hybrid algorithm, similar to STL sort hybrid approach, resulting in a 30% performance gain due to hybrid. In this article the hybrid approach was applied to the N-bit-Radix algorithm, which resulted in higher performance gains. For arrays of 32-bit unsigned and signed integers the gain in performance was over 4X, over 5X for 64-bit, about 6X for 16-bit (but only for arrays smaller than 10K elements), and no gain for 8-bit. This In-place Hybrid N-bit-Radix Sort was further performance optimized by about 10%, by improving the inner loop performance and selecting an optimal threshold of when to switch to Insertion Sort for small sub-arrays. It was then extended to support arrays of 8-bit through 64-bit unsigned and signed integers.
The resulting algorithm was compared with STL sort and Intel’s IPP Radix Sort. For 32-bit integers it was 3-4X faster than STL sort, 2-3X faster for 64-bit, 3-7X faster for 16-bit, and 5-7X faster for 8-bit.
Comparing to Intel’s IPP Radix Sort for 32-bit integers it was comparable in performance for larger array sizes and smaller sizes, but lagged in the mid-size (1K to 100K). For 16-bit and 8-bit it lagged IPP Radix Sort by about 2X and about 4X respectively. 64-bit performance could not be compared since IPP did not implement it.
A trend emerged where arrays of 64-bit elements benefited from the hybrid approach, as well as 32-bit, but 16-bit only up to about 10K elements, and 8-bit not at all. The hybrid combination was that of 256-Radix Sort and Insertion Sort, where the Insertion Sort was invoked when the array size was below a threshold (64 for 64-bit, 100 for 32-bit, and 64 for 16-bit). 256-Radix on average splits the array into 256 bins during each level of recursion (8 levels of recursion for 64-bit, 4 levels for 32-bit, 2 levels for 16-bit, 1 level for 8-bit). Thus, for arrays of 16-bit elements, when the array size is smaller than 64*256=16K then Insertion Sort will be invoked, as this will produce sub-arrays that are smaller than the threshold value of 64 on the second/last recursion. However, if the array is larger than 16K, the sub-arrays will be larger than the threshold, resulting in no invocation of Insertion Sort, but the use of 256-Radix Sort instead for the second level of recursion. For arrays of 32-bit elements, when the array size is smaller than 100*256*256*256=1.68 billion elements then Insertion Sort will be invoked, but not if larger. For arrays of 64-bit elements, this limit point is at 64*2567=”a very large number”. This trend exposes a limit to the benefit of the hybrid approach, which increases as the size of array element increases and depends on the radix as well as the threshold. It also illustrates that N-bit-Radix and Insertion Sort make a good hybrid combination because N-bit-Radix breaks the array into 2N bins at every stage of recursion, getting to small sub-arrays quickly (comparing to STL sort and Binary-Radix Sort, which break the array into 2 bins).
The Counting Sort algorithm, in-place, was briefly described here with implementations shown for 8-bit and 16-bit unsigned integers. It was then augmented by Insertion Sort for smaller array sizes to create a Hybrid Counting Sort. This algorithm was shown to have slightly higher performance than IPP Radix Sort for mid-size and large arrays, but slower for smaller arrays for 8-bit arrays. For 16-bit arrays it was shown to outperform by about 2X for larger arrays, outperform for small arrays, but lagged in performance by as much as 16X for mid-size arrays. Counting Sort was shown to outperform STL sort by 22-30X for 8-bit arrays for mid-size and large arrays, and in the range of 0.5-25X for 16-bit arrays with consistent 22-25X for large arrays. Counting Sort was combined with the Hybrid N-bit-Radix algorithm and invoked for 8-bit and 16-bit unsigned integers.
The approach of making a hybrid non-recursive algorithm, such as the Counting Sort, was not as effective since it only improved performance of the smallest array sizes, whereas when applied to a recursive algorithm such as QuickSort (by STL sort), N-bit-Radix Sort and Binary-Radix Sort performance improvements were experienced for all array sizes (whenever Insertion Sort was invoked).
In-place Hybrid N-bit-Radix Sort performs sorting in-place – i.e., does not require additional memory. STL sort and Counting Sort are also in-place. However, Intel’s IPP Radix Sort is not in-place and requires an additional memory array of equivalent size to the input array.
Stability was not considered for this algorithm, since the current implementation is capable of sorting only arrays of numbers, and stability is not relevant. Intel’s IPP implementations are also only capable of sorting numbers. However, STL sort generic ability is much more advanced than the algorithms presented in this paper and can sort not only numbers, but also other types as well as user-created classes (as long as the comparison operation has been defined). STL sort offers stable and non-stable versions of sorting algorithms.
This article presented a manual exploration of performance optimization space for a sorting algorithm – e.g., found that 256-Radix performed best, which may not hold on other current or future computers. It may be beneficial to automate this process and execute it when software first encounters a particular computer system at which point the algorithm would be adapted to this system to execute most efficiently.
References
[1] V. J. Duvanenko, Algorithm Improvement through Performance Measurement: Part 2.
[2] D. Vandevoorde, N.M. Josuttis, C++ Templates. The Complete Guide, pp. 9-19.

One thought on “In-Place N-bit Radix Sort”