This blog is a repost of an article I wrote in Dr. Dobb’s Journal in October of 2009, since Dr. Dobb’s Journal has ceased operation and its website has broken since then. The article is still available through the amazing web archival of the Wayback machine, as provided below:
V.J. Duvanenko, “Algorithm Improvement through Performance Measurement: Part 2. In-Place Hybrid Binary-Radix Sort”, Oct. 1, 2009
(broken site) https://www.drdobbs.com/architecture-and-design/algorithm-improvement-through-performanc/220300654
A newer and more performant N-bit In-Place Radix Sort is described in https://duvanenko.tech.blog/2022/04/10/in-place-n-bit-radix-sort/
Additional Resources
This algorithm has now been included in a companion electronic book describing other sequential and parallel algorithms: Practical Parallel Algorithms in C++ and C#
Original Article
Radix sorting algorithms do not compare elements of the array to each other and thus are not bound by O(nlogn) performance limit of comparison-based sorting algorithms. In fact, they have O(kn) linear performance. Radix Sort processes array elements one digit at a time, starting ether from the most significant digit (MSD) or the least significant digit (LSD). For example, to sort the following array of 2-digit numbers:

One way to implement Radix Sort is to take the input array and look at the highest digit of each element. Create a bin (a separate array) for 0’s, a bin for 1’s, a bin for 2’s,…, a bin for 9’s. Put all array elements into the bin where the most-significant-digit matches the bin number. Then continue doing this recursively for each bin, based on the next digit. Once all numbers are split into separate bins based on all of their digits, collect them starting with the smallest most significant digit and smallest next digit and so on; for example, collect all digits in the 00 bin, then 01 bin, then 02 bin, …, 09 bin, 10 bin, 11 bin and so on until 99 bin. The result is a sorted array.
One weakness of Radix sort algorithms is the requirement of extra storage (for bins) besides the input array; that is, not being in-place. For instance, Intel’s Integrated Performance Primitives (IPP) library implements a Radix-sort algorithm with the function call prototype of:
IppStatus ippsSortRadixAscend_32u_I(Ipp32u* pSrcDst, Ipp32u* pTmp, Ipp32s len);The temporary vector pTmp is required by the algorithm, with size equal to that of the source vector [1]. Note, that the array is labeled pSrcDst, indicating that the array serves as both the source and the destination for the sorting operation. Intel’s IPP library also implements a non-Radix sort with the function call prototype of:
IppStatus ippsSortAscend_32s_I(Ipp32s* pSrcDst, int len);Binary-Radix
Decimal-Radix is familiar for humans, but binary-radix (base-2) is the smallest useful radix. With binary-radix there are only two possible bins: 0’s bin and 1’s bin. For example, the array is scanned from the beginning to the end while looking at the most-significant-digit, which is the most-significant-bit (MSB) for a binary-radix. If the MSB is a zero, then the array element goes into 0’s bin, or if the MSB is a 1, then the array element goes into 1’s bin.
After splitting the original array into these two bins, the number of elements in 0’s bin plus the number of elements in 1’s bin add up to the number of elements in the original array. The 0’s bin can now be split into 0’s bin and 1’s bin, using the next bit as the sorting decision. The same is done with the 1’s bin. This process continues recursively until all bits have been exhausted. Figure 1 illustrates this procedure.
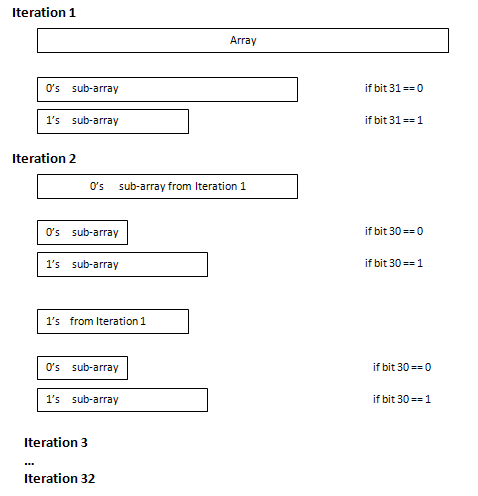
For instance, if the array elements are 32-bit, then 32 passes over each array element will be performed, sorting it into 0’s and 1’s bin for each of the 32-bits. Thus, Binary-Radix Sort is O(kn), where k is the number of bits in each array element and n is the number of array elements. In other words, each array element will be processed 32 times, once for each of its bits.
In-place
In-place is a useful property for a sorting algorithm, where the input array is processed without requiring additional memory, and serves as the output array. If an algorithm is in-place, then it can process larger arrays than an algorithm that is not in-place. This difference was illustrated above with Intel’s IPP functions for Radix Sort, which requires additional memory of equal size to the original array and is not in-place. However, the IPP non-Radix Sort requires no additional memory and is in-place.
Binary Radix-Sort can be made in-place by the following method. Instead of allocating additional memory for 0’s bin and 1’s bin, the original array can be used to store elements of both bins. The 0’s bin is grown from the beginning of the array, and the 1’s bin is grown from the end of the array. When the binning process is done, these two bins will meet somewhere within the array, and will not overlap.
In the next iteration of the algorithm, the bins are created based on the next most-significant-bit, where the 0’s bin from the first iteration is split into two bins: 0’s bin and 1’s bin. The same is done for the 1’s bin from the first iteration. This process continues recursively until all bits of the elements have been processed.
The first iteration of this algorithm, which sorts based on the most-significant-bit (MSB), is demonstrated below. The pointer on the left keeps track of 0’s bin current location. The pointer on the right keeps track of 1’s bin current location.
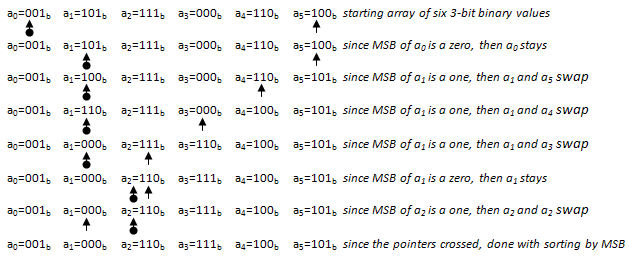
Note that all array elements with MSB of zero are moved to the left side of the array, and the elements with MSB of one are moved to the right side of the array. The array is not completely sorted yet. The algorithm calls itself recursively with the 0’s bin (the left side of the array), and the 1’s bin (the right side of the array), and sort both based on the next bit. Then the algorithm calls itself recursively one more time to sort based on the last bit.
Listing 1 shows an implementation for in-place Binary-Radix Sort algorithm.
// Copyright(c), Victor J. Duvanenko, 2009
// In-place Binary Radix Sort implementations.
#ifndef _InPlaceBinaryRadixSort1_h
#define _InPlaceBinaryRadixSort1_h
// Swap that does not check for self-assignment.
template< class _Type >
inline void _swap( _Type& a, _Type& b )
{
_Type tmp = a;
a = b;
b = tmp;
}
template< class _Type >
inline void _binaryRadixSort_initialUnsigned( _Type* a, long first, long last, _Type bitMask )
{
// Split the provided array range into 0's and 1's bins
long _zerosEndPlusOne = first; // index is one beyond the last 0's bin
long _onesEndMinusOne = last; // index is one before the first 1's bin
for ( ; _zerosEndPlusOne <= _onesEndMinusOne; )
{
if ( 0 == ( bitMask & a[ _zerosEndPlusOne ] )) // 0's bin
{
// this element belongs in the 0's bin
// it stays at its current location and the 0's bin size is increased
_zerosEndPlusOne++;
}
else { // 1's bin
_swap( a[ _zerosEndPlusOne ], a[ _onesEndMinusOne ] ); // move this element to 1's bin
_onesEndMinusOne--; // increase the 1's bin size
}
}
// At this point the provided array portion has been split into 0's bin and 1's bin
// Recursively call to sort this 0's bin and this 1's bin using the next bit lower
bitMask >>= 1;
if ( bitMask != 0 ) // end recursion when all the bits have been processes
{
if ( first < ( _zerosEndPlusOne - 1 ))
_binaryRadixSort_initialUnsigned( a, first, _zerosEndPlusOne - 1, bitMask );
if (( _onesEndMinusOne + 1 ) < last )
_binaryRadixSort_initialUnsigned( a, _onesEndMinusOne + 1, last, bitMask );
}
}
inline void binaryRadixSortInPlace_initialUnsigned( unsigned long* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
unsigned long bitMask = 0x80000000;
_binaryRadixSort_initialUnsigned( a, 0, a_size - 1, bitMask );
}
endif // _InPlaceBinaryRadixSort_h
The outermost routine binaryRadixSortInPlace_initialUnsigned() sets the initial bit-mask to select the most significant bit and calls a template function _binaryRadixSort_initialUnsigned(). This core function splits the provided array range, between first and last elements, into 0’s bin and 1’s bin, in-place. Then it shifts the bit-mask to the right to select the next bit down, and calls itself recursively twice: once for the 0’s bin, and the second time for the 1’s bin. During the splitting process the algorithm uses the _swap() generic function template to move the element to 1’s bin.
Table 1 shows performance benchmarks of in-place Binary-Radix Sort, STL sort, and Intel’s IPP Radix-sort functions for an array of random unsigned 32-bit elements. Intel IPP library also has a non-Radix sort function, which handles a variety of input data types, but not 32-bit unsigned integers [1].
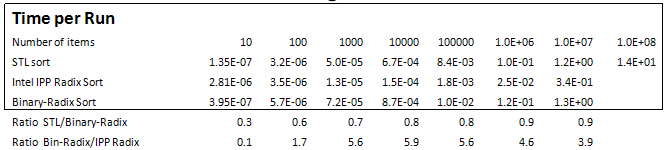
These measurements and the ratios computed from them show that Binary-Radix Sort approaches STL sort in performance for random input data sets. Intel’s IPP Radix Sort outperformed Binary-Radix Sort by about 4-6X, for 32-bit unsigned numbers.
Test Setup
One method for verification of correctness is to compare algorithm implementations to STL sort for assurance of equivalent results, but that assumes STL sort is correct. To not rely on correctness of STL sort requires implementing a correctness test for sorting algorithms. Correctness requires that array[i] ≤ array[i+1] for all elements of the array, which is simple to check. Of course, comparison to results from STL sort would be a useful redundant verification. These two tests were used for all implemented routines, including Intel’s IPP library routines. Boundary cases of the input arrays of size 0 and 1 were also tested.
The performance comparison setup was as follows:
- Visual Studio 2008, optimization project setting is set to optimize neither speed or size, and inline any suitable function.
- Intel Core 2 Duo CPU E8400 at 3 GHz (64 Kbytes L1 and 6 Mbytes L2 cache).
- 14-stage pipeline with 1,333 MHz front-side bus.
- 2 GB of system memory (dual-channel 64-bits per channel, 800 MHz DDR2).
- motherboard is DQ35JOE.
Random numbers were generated by using the following method for each element in the array:
// each call to rand() produces 15-bit random number.
unsigned long tmp = ((unsigned long)rand()) << 30 |
((unsigned long)rand())<< 15 |
((unsigned long)rand());
The arrays were all checked for percentage of unique values, which were all above 95% for arrays filled with 32-bit unsigned values. The range of min and max were also checked for each array, which were between 0 and near the max value for 32-bit unsigned numbers.
Performance was measured by always processing 100 million elements. When 10 element arrays were being measured, then 10 million of them were allocated. When 100 element arrays were being measured, then 1 million of them were allocated, and so on. A different random-number generator seed was used for each array, but the same seeds were used across all algorithms. Time-stamp was taken before sorting the 10 million arrays and also after. The average value across all arrays is the value reported.
Hybrid
The STL sort implementation combines three different sorting algorithms to extract the best attributes of each, resulting in superior overall performance. STL sort combines the best of QuickSort, Heap Sort, and Insertion Sort algorithms, enabling each under different conditions, where each excels over others. It starts out using QuickSort for 1.5*log2(n) divisions of recursion depth, followed by Heap Sort if the resulting divisions still hold more than 32 elements, and Insertion Sort if they hold between 32 and 2 elements. Insertion Sort provides good cache locality at the leaf nodes of the binary recursion tree, and it is adaptive to input data [4]. Ending recursion at about 32 elements avoids the function call and return overhead when the number of elements is small.
The same good ideas can be applied to Radix Sort (Binary or higher radix). Listing 2 shows such an implementation, which uses a version of Insertion Sort from [4], also included in Listing 2.
#ifndef _InPlaceBinaryRadixSort2_h
#define _InPlaceBinaryRadixSort2_h
// Swap that does not check for self-assignment.
template< class _Type >
inline void _swap( _Type& a, _Type& b )
{
_Type tmp = a;
a = b;
b = tmp;
}
template< class _Type >
inline void insertionSortSimilarToSTLnoSelfAssignment( _Type* a, unsigned long a_size )
{
for ( unsigned long i = 1; i < a_size; i++ )
{
if ( a[ i ] < a[ i - 1 ] ) // no need to do (j > 0) compare for the first iteration
{
_Type currentElement = a[ i ];
a[ i ] = a[ i - 1 ];
unsigned long j;
for ( j = i - 1; j > 0 && currentElement < a[ j - 1 ]; j-- )
{
a[ j ] = a[ j - 1 ];
}
a[ j ] = currentElement; // always necessary work/write
}
// Perform no work at all if the first comparison fails - i.e. never assign an element to itself!
}
}
inline void _binaryRadixSort_wInsertion( unsigned long* a, long first, long last, unsigned long bitMask )
{
if (( last - first ) > 32 )
{
// Split the provided array range into 0's and 1's sub-ranges
long _zerosEndPlusOne = first; // index is one beyond the last 0's portion
long _onesEndMinusOne = last; // index is one before the first 1's portion
for ( ; _zerosEndPlusOne <= _onesEndMinusOne; )
{
if ( 0 == ( bitMask & a[ _zerosEndPlusOne ] )) // 0's portion
{
// nothing to do, as this is our 0's portion of the array
_zerosEndPlusOne++;
}
else { // 1's portion
_swap( a[ _zerosEndPlusOne ], a[ _onesEndMinusOne ] );
_onesEndMinusOne--;
}
}
// Recursively call to sort 0's portion and 1's portion using the next bit lower
bitMask >>= 1;
if ( bitMask != 0 )
{
if ( first < ( _zerosEndPlusOne - 1 ))
_binaryRadixSort_wInsertion( a, first, _zerosEndPlusOne - 1, bitMask );
if (( _onesEndMinusOne + 1 ) < last )
_binaryRadixSort_wInsertion( a, _onesEndMinusOne + 1, last, bitMask );
}
}
else {
insertionSortSimilarToSTLnoSelfAssignment( &a;[ first ], last - first + 1 );
}
}
inline void binaryRadixSortInPlace_wInsertion( unsigned long* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
unsigned long bitMask = 0x80000000;
_binaryRadixSort_wInsertion( a, 0, a_size - 1, bitMask );
}
endif // _InPlaceBinaryRadixSort_h
Tables 2 through 5 and Graph 1 compare performance of Hybrid Binary-Radix Sort with STL sort and IPP Radix Sort.
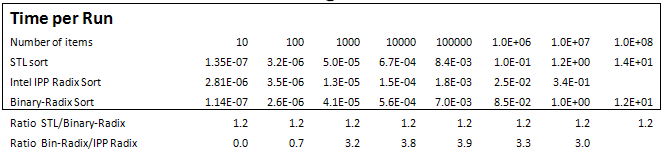
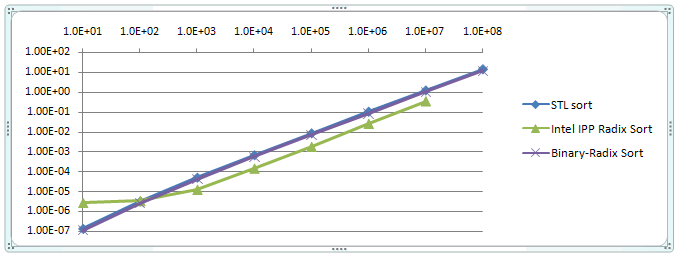


These measurements and the ratios computed from them, show that the Hybrid Binary-Radix Sort consistently outperforms STL sort for random input data set, by 20%, but not for increasing and decreasing input data sets, where it lags by up to 40%. Intel’s IPP Radix Sort outperformed all others by at least 3X for random input data, but lagged STL sort for other data input statistics.
Improvements
Several inefficiencies are noticeable in the sorting example of six 3-bit numbers above:
- In the next-to-last step of the algorithm, the element a2 is swapped with itself.
- In lines 3 and 4, the swaps are performed between elements which both belong to the 1’s bin.
The first improvement can be implemented using a method similar to that used in [4], where self-assignment was eliminated without performing additional work. In this case, the last loop can be extracted from the for loop by changing the comparison from &b;><= to <. The tricky detail here is that:
if (_zerosEndPlusOne == _onesEndMinusOne )is not necessary and can be removed, because all recursion calls check to make sure that each bin holds at least two elements. Thus, the for loop is guaranteed to run for at least one iteration, leaving the “==” condition as the only work left after the for loop; for example, the only work left is when a single element is left (and a swap is not necessary). Note that in this case, the amount of work was actually reduced to handle this condition, since the “==” comparison was removed. This optimization resulted in 4-5% performance improvement for random input data set of 32-bit unsigned integers. The implementation is in Listing 3.
#ifndef _InPlaceBinaryRadixSort3_h
#define _InPlaceBinaryRadixSort3_h
// Swap that does not check for self-assignment.
template< class _Type >
inline void _swap( _Type& a, _Type& b )
{
_Type tmp = a;
a = b;
b = tmp;
}
template< class _Type >
inline void insertionSortSimilarToSTLnoSelfAssignment( _Type* a, unsigned long a_size )
{
for ( unsigned long i = 1; i < a_size; i++ )
{
if ( a[ i ] < a[ i - 1 ] ) // no need to do (j > 0) compare for the first iteration
{
_Type currentElement = a[ i ];
a[ i ] = a[ i - 1 ];
unsigned long j;
for ( j = i - 1; j > 0 && currentElement < a[ j - 1 ]; j-- )
{
a[ j ] = a[ j - 1 ];
}
a[ j ] = currentElement; // always necessary work/write
}
// Perform no work at all if the first comparison fails - i.e. never assign an element to itself!
}
}
template< class _Type >
inline void _binaryRadixSortNoSelfAssignment_unsigned( _Type* a, long first, long last, _Type bitMask )
{
// Split the provided array range into 0's and 1's portions
long _zerosEndPlusOne = first; // index is one beyond the last 0's portion
long _onesEndMinusOne = last; // index is one before the first 1's portion
for ( ; _zerosEndPlusOne < _onesEndMinusOne; )
{
if ( 0 == ( bitMask & a[ _zerosEndPlusOne ] )) // 0's portion
{
// this element belongs in the 0's portion
// so just keep it in its place and grow the 0's portion size
_zerosEndPlusOne++;
}
else { // 1's portion
_swap( a[ _zerosEndPlusOne ], a[ _onesEndMinusOne ] ); // move this element to 1's portion
_onesEndMinusOne--;
}
}
if ( 0 == ( bitMask & a[ _zerosEndPlusOne ] )) // 0's portion
{
_zerosEndPlusOne++;
}
else { // 1's portion
_onesEndMinusOne--; // No swap is needed, since it's self-assignment
}
// Recursively call to sort 0's portion and 1's portion using the next bit lower
bitMask >>= 1;
if ( bitMask != 0 ) // end recursion when all the bits have been processes
{
if ( first < ( _zerosEndPlusOne - 1 )) // call only if number of elements >= 2
_binaryRadixSortNoSelfAssignment_unsigned( a, first, _zerosEndPlusOne - 1, bitMask );
if (( _onesEndMinusOne + 1 ) < last ) // call only if number of elements >= 2
_binaryRadixSortNoSelfAssignment_unsigned( a, _onesEndMinusOne + 1, last, bitMask );
}
}
inline void binaryRadixSortInPlaceNoSelfAssignment_unsigned( unsigned long* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
unsigned long bitMask = 0x80000000;
_binaryRadixSortNoSelfAssignment_unsigned( a, 0, a_size - 1, bitMask );
}
endif // _InPlaceBinaryRadixSort_h
The second improvement was prompted by [5] and shows up clearly in the sorting example above. Listing 4 shows an implementation which removes redundant swaps of elements that both belong to the 1’s bin. Instead, the algorithm switches to growing the 1’s bin while looking for a 0’s bin element to swap with.
#ifndef _InPlaceBinaryRadixSort4_h
#define _InPlaceBinaryRadixSort4_h
// Swap that does not check for self-assignment.
template< class _Type >
inline void _swap( _Type& a, _Type& b )
{
_Type tmp = a;
a = b;
b = tmp;
}
template< class _Type >
inline void insertionSortSimilarToSTLnoSelfAssignment( _Type* a, unsigned long a_size )
{
for ( unsigned long i = 1; i < a_size; i++ )
{
if ( a[ i ] < a[ i - 1 ] ) // no need to do (j > 0) compare for the first iteration
{
_Type currentElement = a[ i ];
a[ i ] = a[ i - 1 ];
unsigned long j;
for ( j = i - 1; j > 0 && currentElement < a[ j - 1 ]; j-- )
{
a[ j ] = a[ j - 1 ];
}
a[ j ] = currentElement; // always necessary work/write
}
// Perform no work at all if the first comparison fails - i.e. never assign an element to itself!
}
}
template< class _Type >
inline void _binaryRadixSort_wInsertionMinSwapsSymmetric_unsignedOnly( _Type* a, long first, long last, _Type bitMask )
{
if (( last - first ) > 32 )
{
// Split the provided array range into 0's and 1's bins
long _zerosEndPlusOne = first; // index is one beyond the last 0's portion
long _onesEndMinusOne = last; // index is one before the first 1's portion
for ( ; _zerosEndPlusOne <= _onesEndMinusOne; )
{
if ( 0 == ( bitMask & a[ _zerosEndPlusOne ] )) // 0's bin
{
_zerosEndPlusOne++; // grow 0's bin
}
else { // 1's portion
do // Locate an element that belongs in 0's portion, to eliminate unnecessary swaps
{
if ( 0 != ( bitMask & a[ _onesEndMinusOne ]))
{
_onesEndMinusOne--; // grow 1's bin of the array
}
else
{
_swap( a[ _zerosEndPlusOne ], a[ _onesEndMinusOne ] );
_onesEndMinusOne--;
_zerosEndPlusOne++; // grow 0's and 1's - found a perfect swap match
break; // switch back to the 0's bin
}
} while( _zerosEndPlusOne <= _onesEndMinusOne );
}
}
// Recursively call to sort 0's portion and 1's portion using the next bit lower
bitMask >>= 1;
if ( bitMask != 0 )
{
if ( first < ( _zerosEndPlusOne - 1 ))
_binaryRadixSort_wInsertionMinSwapsSymmetric_unsignedOnly( a, first, _zerosEndPlusOne - 1, bitMask );
if (( _onesEndMinusOne + 1 ) < last )
_binaryRadixSort_wInsertionMinSwapsSymmetric_unsignedOnly( a, _onesEndMinusOne + 1, last, bitMask );
}
}
else {
insertionSortSimilarToSTLnoSelfAssignment( &a;[ first ], last - first + 1 );
}
}
inline void binaryRadixSortInPlace( unsigned char* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
unsigned char bitMask = 0x80;
_binaryRadixSort_wInsertionMinSwapsSymmetric_unsignedOnly( a, 0, a_size - 1, bitMask );
}
inline void binaryRadixSortInPlace( unsigned short* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
unsigned short bitMask = 0x8000;
_binaryRadixSort_wInsertionMinSwapsSymmetric_unsignedOnly( a, 0, a_size - 1, bitMask );
}
inline void binaryRadixSortInPlace( unsigned long* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
unsigned long bitMask = 0x80000000;
_binaryRadixSort_wInsertionMinSwapsSymmetric_unsignedOnly( a, 0, a_size - 1, bitMask );
}
inline void binaryRadixSortInPlace( unsigned __int64* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
unsigned __int64 bitMask = 0x8000000000000000ui64;
_binaryRadixSort_wInsertionMinSwapsSymmetric_unsignedOnly( a, 0, a_size - 1, bitMask );
}
endif // _InPlaceBinaryRadixSort_h
When it finds the 0’s element, it swaps knowing that both elements involved are going to their final destinations — into their respective bins. These two elements will not be swapped again (growing 0’s and 1’s bin after the swap). Modified algorithm steps are outlined as follows:
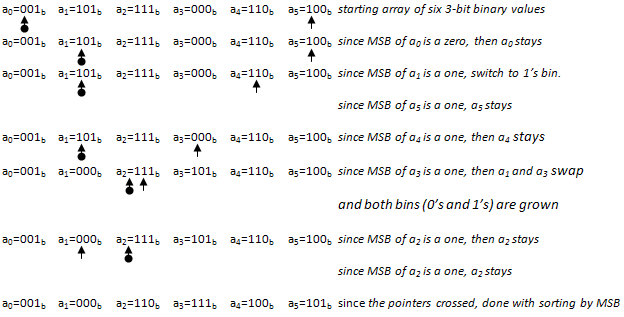
This improvement eliminated redundant swaps between elements that both belong to the 1’s bin, in the initial implementation. The number of steps to complete the sort has been reduced dues to the swaps becoming “perfect” (moving both elements of the swap to their respective bins), which allowed for both bins to be grown; see line 5 of example above. Also, self-assignment has been removed in both cases: when the last element is in the 0’s bin or in 1’s bin, that bin is grown without self-assignment (which can be seen in the implementation).
This improvement also fixed an asymmetry in the algorithm where in the 0’s bin the current pointer was advanced without swapping if the element belonged in the 0’s bin, but was not the case for 1’s bin. With the modification, if the element belonged in the 1’s bin and was already in the 1’s bin location, it was left there and the pointer was advanced to keep searching for an element that did not belong in the 1’s bin; for example, looking for a “perfect” swap candidate (where both elements were in the wrong bin before the swap).
Another ending condition is possible and is shown below:
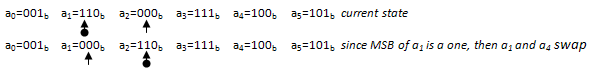
This ending condition also ends well, with a single perfect swap and both bins being grown.
Performance measurements of the final version of Hybrid Binary-Radix Sort along with other algorithms are shown in Tables 5, 6, and 7. The Intel IPP library does not have an implementation of 32-bit unsigned non-Radix sorting, and for 64-bit unsigned sorting.
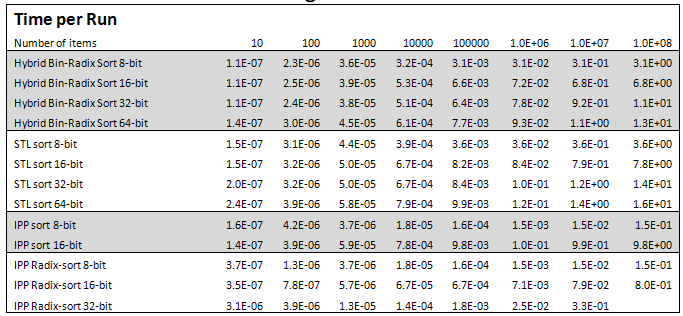
Table 5 provides a lot of information, with several notables:
- IPP Radix Sort is significantly faster than all other algorithms for 8-, 16-, and 32-bit unsigned — 20X faster, 8X and about 3X faster respectively than the closest competitor.
- IPP sort performance for 8-bit seems to be the same as IPP Radix Sort, but with the benefit of being in-place.
- IPP sort for 16-bit unsigned is significantly worse in performance than the 8-bit version — 65X.
- Hybrid Binary-Radix Sort outperforms STL sort for all data sizes, and IPP sort for 16-bit by at least 15%.
- Tables 6 and 7 show that Hybrid Binary-Radix outperforms STL sort and IPP Radix Sort by at least 30% for increasing and decreasing input data sets.
- Hybrid Binary-Radix Sort increased in performance over 40% from the initial implementation.
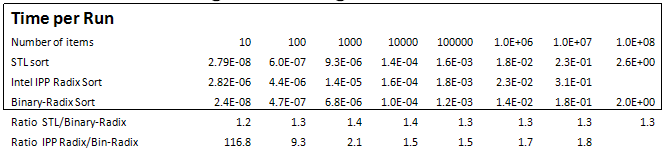
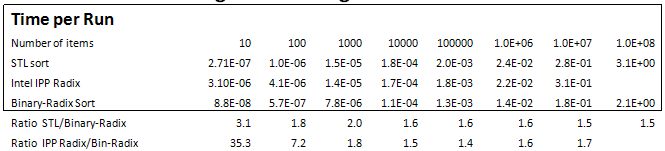
Since the generic implementation, through overloaded functions, is data-type-aware it is possible to provide a type-dependent threshold value that controls the switch point for using Insertion Sort. Brief experiments did not indicate this to be promising, but more detailed investigation may be fruitful.
Signed
Signed integers use 2’s complement format shown below, with the binary representation on the left and its decimal value on the right:

Note that the most-significant-bit (MSB) serves as the sign bit. However, its meaning is opposite of what is needed for sorting. If unsigned Binary-Radix Sort algorithm is used, then negative numbers would be interpreted as larger than positive numbers, since negatives have the MSB set to a 1. However, the rest of the bits have the same meaning as unsigned numbers — a 1 is bigger than a 0. Thus, for signed numbers only the MSB must be treaded specially, with the opposite meaning — a 0 is larger than a 1. Listing 5 shows an implementation, which treats the sign bit (the MSB) of signed numbers in the opposite manner, followed by recursive calls to the unsigned core routine for the rest of the bits.
#ifndef _InPlaceBinaryRadixSort5_h
#define _InPlaceBinaryRadixSort5_h
// Swap that does not check for self-assignment.
template< class _Type >
inline void _swap( _Type& a, _Type& b )
{
_Type tmp = a;
a = b;
b = tmp;
}
// A set of logical right shift functions to work-around the C++ issue of performing an arithmetic right shift
// for >>= operation on signed types.
inline char logicalRightShift( char a, unsigned long shiftAmount )
{
return (char)(((unsigned char)a ) >> shiftAmount );
}
inline short logicalRightShift( short a, unsigned long shiftAmount )
{
return (short)(((unsigned short)a ) >> shiftAmount );
}
inline long logicalRightShift( long a, unsigned long shiftAmount )
{
return (long)(((unsigned long)a ) >> shiftAmount );
}
inline __int64 logicalRightShift( __int64 a, unsigned long shiftAmount )
{
return (__int64)(((unsigned __int64)a ) >> shiftAmount );
}
template< class _Type >
inline void insertionSortSimilarToSTLnoSelfAssignment( _Type* a, unsigned long a_size )
{
for ( unsigned long i = 1; i < a_size; i++ )
{
if ( a[ i ] < a[ i - 1 ] ) // no need to do (j > 0) compare for the first iteration
{
_Type currentElement = a[ i ];
a[ i ] = a[ i - 1 ];
unsigned long j;
for ( j = i - 1; j > 0 && currentElement < a[ j - 1 ]; j-- )
{
a[ j ] = a[ j - 1 ];
}
a[ j ] = currentElement; // always necessary work/write
}
// Perform no work at all if the first comparison fails - i.e. never assign an element to itself!
}
}
template< class _Type >
inline void _binaryRadixSort_wInsertionMinSwapsSymmetric_signedOnly( _Type* a, long first, long last, _Type bitMask )
{
if (( last - first ) > 32 )
{
// Split the provided array range into 0's and 1's bins
long _zerosEndPlusOne = first; // index is one beyond the last 0's portion
long _onesEndMinusOne = last; // index is one before the first 1's portion
for ( ; _zerosEndPlusOne <= _onesEndMinusOne; )
{
if ( 0 != ( bitMask & a[ _zerosEndPlusOne ] )) // 0's bin
{
_zerosEndPlusOne++; // grow 0's bin
}
else { // 1's portion
do // Locate an element that belongs in 0's portion, to eliminate unnecessary swaps
{
if ( 0 == ( bitMask & a[ _onesEndMinusOne ]))
{
_onesEndMinusOne--; // grow 1's bin of the array
}
else
{
_swap( a[ _zerosEndPlusOne ], a[ _onesEndMinusOne ] );
_onesEndMinusOne--;
_zerosEndPlusOne++; // grow 0's and 1's - found a perfect swap match
break; // switch back to the 0's bin
}
} while( _zerosEndPlusOne <= _onesEndMinusOne );
}
}
// Recursively call to sort 0's portion and 1's portion using the next bit lower
bitMask = logicalRightShift( bitMask, 1 );
if ( bitMask != 0 )
{
if ( first < ( _zerosEndPlusOne - 1 ))
_binaryRadixSort_wInsertionMinSwapsSymmetric_unsignedOnly( a, first, _zerosEndPlusOne - 1, bitMask );
if (( _onesEndMinusOne + 1 ) < last )
_binaryRadixSort_wInsertionMinSwapsSymmetric_unsignedOnly( a, _onesEndMinusOne + 1, last, bitMask );
}
}
else {
insertionSortSimilarToSTLnoSelfAssignment( &a;[ first ], last - first + 1 );
}
}
inline void binaryRadixSortInPlace( char* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
char bitMask = (char)0x80;
_binaryRadixSort_wInsertionMinSwapsSymmetric_signedOnly( a, 0, a_size - 1, bitMask );
}
inline void binaryRadixSortInPlace( short* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
short bitMask = (short)0x8000;
_binaryRadixSort_wInsertionMinSwapsSymmetric_signedOnly( a, 0, a_size - 1, bitMask );
}
inline void binaryRadixSortInPlace( long* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
long bitMask = 0x80000000;
_binaryRadixSort_wInsertionMinSwapsSymmetric_signedOnly( a, 0, a_size - 1, bitMask );
}
inline void binaryRadixSortInPlace( __int64* a, unsigned long a_size )
{
if ( a_size < 2 ) return;
__int64 bitMask = 0x8000000000000000i64;
_binaryRadixSort_wInsertionMinSwapsSymmetric_signedOnly( a, 0, a_size - 1, bitMask );
}
endif // _InPlaceBinaryRadixSort_h
This implementation uses overloaded functions to handle all signed types from 8-bit to 64-bits. This fits nicely with the unsigned functions to provide a consistent and fairly generic implementation that handles unsigned and signed types using the same interface, as well as the same function name. Correctness of the signed implementation was tested using the same test procedure as for unsigned versions of the algorithm.
Signed implementation has another slight difference — it uses an overloaded function logicalRightShift(). This function was necessary because C++ defines right shift operation “>>” for signed number as an arithmetic shift and not a logical shift, which is not the behavior that is needed. Interestingly, Java defines a “>>>” operator, which implements a logical shift on signed numbers [6] and “>>” performs an arithmetic shift. It’s unfortunate that C++ is stuck with this behavior, most likely for backwards compatibility with C, since it would be clearer to have “>>” mean logical shift and “/2” mean arithmetic shift for both unsigned and signed integers. Capable compilers already optimize “integer divide by power of 2 constant” as an arithmetic shift.
Comparing Order
Comparing algorithms of dissimilar performance order, such as O(nlogn) for STL sort and O(kn) for Radix-Sort, should provide insight about when one algorithm is expected to be better than another. The comparison is easier to see if the orders are put in a similar form, such as O(log2(n)*n) and O(k*n). Both formulas have an n term in common, and thus the comparison is between log2(n) and k [3]. Another way to see this is to divide the two formulas. In this case, n cancels out and log2(n)/k ratio remains. If log2(n) is bigger than k, the ratio will be bigger than 1. If k is bigger, the ratio will be less than 1.
Table 8 demonstrates this relationship. It shows that log2(n) increases by one when n doubles — which follows from one of the rules of logarithms, where log( m*n ) = log(m) + log(n). In this case, log2( 2*n ) = log2(2) + log2(n) = 1 + log2(n). The second portion of the table shows that for log2(n)to double, n has to square, which follows from another rule of logarithms, where m*log(n) = log(nm), where m=2 in this case.

In Table 8 one of the entries is log2(4.3*109)=32 — for example, n = 4.3E+9, or 4.3 billion. For this case, when the array contains 4.3 billion elements, then O(log(n)*n ) = 32*4.3*109, which is the estimate of the number of comparisons for the STL sort algorithm.
For Binary-Radix Sort, the order is O(k*n), where k is the number of bits in each element. If the elements are 32-bits each, then O(k*n) = 32*4.3*109 operations for an array with 4.3 billion elements. In this case, the estimates for STL sort and Binary-Radix Sort are equal. For the case of 8-bit elements, Binary-Radix Sort estimate is 8*4.3*109, whereas STL estimate stays at 32*4.3*109, predicting Binary-Radix Sort to be faster. For the case of 64-bit elements, the Binary-Radix-Sort estimate is 64*4.3*109, whereas STL estimate stays at 32*4.3*109, predicting STL sort to be faster.
These examples demonstrate that STL sort performance is estimated only from the number of elements in the array and not their size, whereas Binary-Radix Sort is estimated from the number of bits of each element and the number of elements. The order formulas predict that Binary-Radix Sort should be faster than STL sort (actually any optimal comparison sort) when the elements are made of a few bits, but that STL sort should be faster when the element size is large.
Tables 9 show measured performance comparisons. Intel IPP does not implement 8-bit and 64-bit signed integer sorting in non-Radix and Radix sorting.
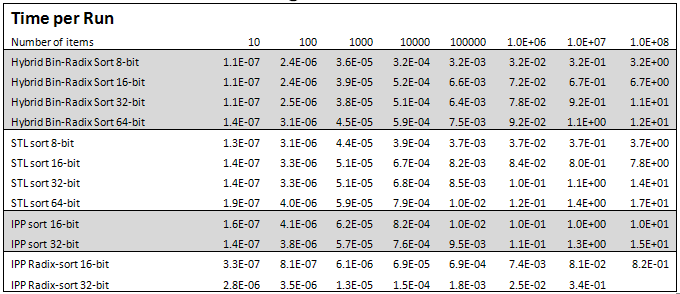
Table 9 provides a lot of information, with several notables:
- All algorithms performed consistently with their unsigned counterparts (when existed), where signed and unsigned performance was nearly equal.
- IPP Radix Sort is significantly faster than all other algorithms for 16 and 32-bit signed — 8X and about 3X faster respectively than the closest competitor.
- Order predictions hold accurately for Hybrid Binary-Radix Sort for 8, 16 and 32-bit cases, where the performance decreases by 2X as the number of bits (k) increases by 2X. However, for 64-bit case the performance does not decrease by 2X as predicted, but increases by about 16%.
- Order prediction is not accurate for STL sort, expecting the performance not to depend on the size of array elements, but only on the number of elements. However, STL sort performance decreases by 2X as the number of bits increases by 2X, for 8, 16 and 32-bit cases, but not for 64-bit.
- Order prediction for STL sort to beat Binary-Radix Sort did not hold for up to 64-bits.
At first it may seem that Binary-Radix sort is a good candidate for multicore and multithreading. It splits the data set into two portions and then splits those further recursively. However, the split of the array is data dependent. In other words, the split will not always be even, which leads to uneven load balancing. This may be one of the reasons that Intel did not multithread its Radix-Sort implementation.
Conclusions
In-place Hybrid Binary-Radix Sort (MSD-style) algorithm was developed and improved through several performance optimizations. Insertion Sort was used at the bottom of the recursion tree. Over 40% performance improvement was achieved from the initial implementation, by removing redundant operations. The implementation was extended to handle unsigned and signed integers from 8-bits to 64-bits. A data-type-aware generic interface, overloaded functions, was used to encapsulate unique unsigned and signed implementations under a common interface. The resulting algorithm compared favorably with STL sort implementation, outperforming it by at least 15% for random input data and 32 & 64-bit increasing and decreasing data sets.
Comparison to Intel’s IPP sort (in-place) and Radix sort (not in-place) was also performed, where IPP’s Radix Sort was found to perform 20X, 8X and about 3X faster for 8-bit, 16-bit and 32-bit unsigned respectively. Hybrid Binary-Radix Sort outperformed IPP’s sort for 16 and 32-bit data types, but lagged by 20X for 8-bit unsigned data type.
Inconsistencies in using algorithm order for performance prediction were found for STL sort for most data sizes, whereas Hybrid Binary-Radix Sort was predicted consistently except for 64-bit data size.
A further hybrid in-place algorithm can be evolved by combining the best attributes of Intel’s IPP algorithms with in-place Hybrid Binary-Radix Sort. For instance, the high-performance IPP 8-bit in-place sort can be integrated under the generic interface developed. For the 8-bit unsigned overloaded function implementation, Intel’s IPP sort function would be called. The combined algorithm would retain its generic interface, but yet would have data type specific optimized implementations. This leads to “generic data type adaptive” algorithms, which would retain a generic interface and adapt to perform optimally for each data type. Purely generic algorithms miss this opportunity, as well as the 20X performance improvement shown for 8-bit data types.
Floating-point support would be a nice extension. Intel IPP sorting routines support floating-point: single and double-precision. Creating a more sophisticated generic implementation, such as STL’s, would allow custom classes to be sorted. The use of iterators would reduce the number of items passed to each level of recursion from currently 4 down to 3 (first and last iterator, and bitMask), possibly improving performance.
References
[1] Intel Integrated Performance Primitives for Intel Architecture, Reference Manual, Volume 1: Signal Processing, August 2008, pp. 5-57 – 5-61.
[2] http://en.wikipedia.org/wiki/Radix_sort
[3] Jim Vaught of Arxan Defense Systems — personal discussion.
[4] V. J. Duvanenko, Algorithm Improvement through Performance Measurement: Part 1, Dr. Dobb’s
[5] Scott Miller of Arxan Defense Systems — personal discussion.
