So far, we’ve measured performance of random number generators in software on a single CPU core, on multiple cores, on a powerful laptop, on a workstation, as well as on mobile and desktop graphics processors (GPU). Let’s compare them to each other, fair or not.
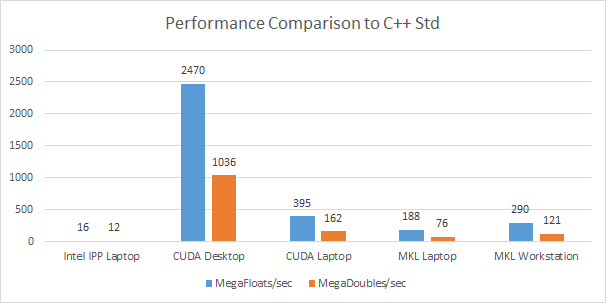
The above graph shows the number of times each random number generator is faster than the C++ standard library generator. From each library, such as Intel IPP, and Intel MKL, and CUDA cuRAND, the fastest generator was chosen to show the largest performance gain. CPU generated random values in system memory, and GPU generated random values in graphics memory – i.e. closest memory to each generator. Large arrays of single and double precision floating-point values were generated.
On the desktop, GeForce 1070 GPU was used, while on the laptop GeForce 950M. Both ran CUDA 8.0 using cuRAND library. On the CPU, Intel MKL 2017 update 2 was used, running on multi-core processors: on laptop and workstation. Intel IPP library ran on the quad-core laptop.
GeForce 1070 GPU leaves no doubts and blows every other generator away for both single and double precision floating point number generation, topping out nearly 2500X faster than C++ standard library generator running on a single core of a quad-core laptop. Even if C++ standard generator was to be multi-threaded to run on all four cores, the GPU would still run over 600X circles around the C++ generator.
MKL running on quad-core laptop comes close to the performance of the laptop GPU (950M) – within nearly 2X. MKL runs about 50% faster on a workstation class CPU with more memory bandwidth, since most algorithms are limited by memory bandwidth. The IPP library lags significantly behind MKL by more than 10X.
The performance gain of these high performance optimized algorithms libraries over the standard C++ libraries for generating random floating-point values is spectacular. It is not just 20-50% gain, but is hundreds and even thousands times faster. When going faster is critical, these libraries are well worth a look, since they are free and are cross platform.
Caveats
The GeForce GPUs generated random numbers in graphics memory and did not include the additional time needed to transfer the resulting array from graphics memory to system memory. The multi-core CPUs generated random values in system memory and did not include the additional time needed to transfer the array from system memory to graphics memory.
Depending where the array of random values is needed next, whether in system memory or in graphics memory, the time to transfer these values needs to be included. The algorithm that these values are intended for could be running on the GPU, the CPU or even both. Minimizing transfer time overhead will be important for peak overall performance.
