Intel’s 2017 MKL random number generator functions do not provide parallel functions, but provide mechanisms to support multi-threaded generation. Some of these algorithms are bound by memory performance and run significantly faster when the array fits in the processor cache. These algorithms should scale well running on multiple cores when each array fits in non-shared levels of cache. But first, let’s see how well the algorithms scale from single-core to multi-core for very large array sizes.
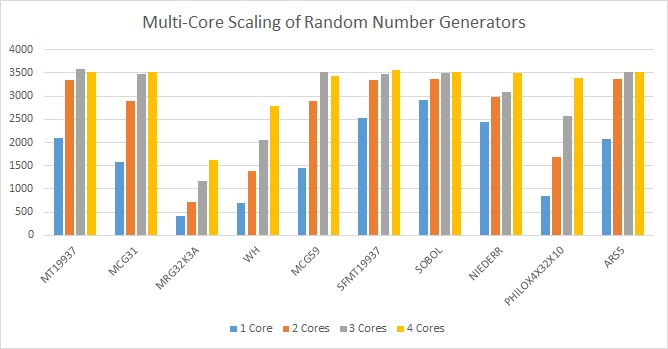
The above graph compares 2017 MKL random number generators which support multi-threaded generation. The slower algorithms, such as MRG32K3A, WH, and PHILOX3X32x10 scale linearly on my quad-core laptop i5-6300HQ CPU. The faster algorithms, such as MT19937, MCG31, MCG59, SFMT19937, NIEDERR, and ARS5, scale linearly until the memory bandwidth limit is reached. All of the algorithms scale well, up to the memory bandwidth limit, when generating single precision 32-bit floating-point random values in the range of 0.0 to 1.0 (i.e. floats).
The memory bandwidth limits the performance of these generators to about 3.5 GigaFloats/sec. It’s anticipated that these generators will run faster on a machine with higher memory bandwidth, or running inside CPU cache when using smaller array sizes which fit inside the cache, where higher memory bandwidth is available.
These measurements were performed with 500 MegaFloats array size, which does not fit into the CPU cache, but fits into 16 GigaBytes of system memory.
The following graph show multi-core scaling for MKL random number generators for double precision floating-point:
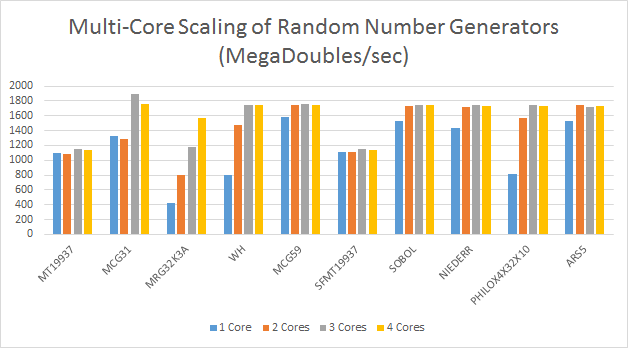
For doubles, multi-core scaling is not as consistent as it is for single precision floating-point random values. MT19937 and SFMT19937 algorithms do not scale beyond a single core. MCG31, MCG59, SOBOL, NIEDERR, and ARS5, reach memory bandwidth limit with two or more cores, making scaling beyond that point not worthwhile for this laptop. Since the laptop CPU (i5-6300HQ) support two channels of DD4 memory, for large arrays of random double precision floating-point values, memory bandwidth is the main performance limiter. Let’s see if performance scales further on a workstation class CPU with four channels of DDR4 memory, and more cores.
The following two graphs show performance on a workstation with a Xeon E5 1650 6-core CPU with Hyperthreading.
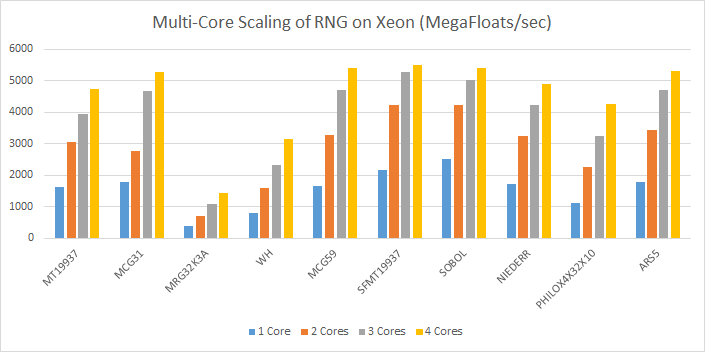
Performance increased from 3.5 GigaFloats/sec to over 5 GigaFloats/sec, as memory bandwidth increased from 2 channels of DDR4 to 4 channels. The same goes for generating double precision floating-point random numbers, increase from 1.7 GigaDoubles/sec to 2.7 GigaDoubles/sec with additional system memory bandwidth, as the following graph shows:

Let’s see how high performance can go when reducing the array size to fit inside the CPU cache.

The above graph shows that many of the algorithms scale well when the bandwidth limit is lifted. Seven algorithms generated more than 5 GigaDoubles/sec on a quad-core processor. Three generated more than 6 GigaDoubles/sec, and one generated more than 7 GigaDoubles/sec. This benchmark used 4 out of the 6 available cores in the Xeon CPU. Thus, performance should reach 10 GigaDoubles/sec when all 6 cores are being used. This level of performance is 4X faster than Xeon processor with 4 channels of external memory, because bandwidth between the CPU and internal levels of cache is higher than bandwidth of system memory.
Deeper Details
2017 MKL supports parallel/multi-threaded random generator functions to produce the same array of random values as the non-parallel generators. For this, two methods are provided: skip ahead and leap frog. Skip ahead splits the array into N contiguous even parts, enabling N-way parallel generation. Leap frog interleaves the array by N. Details of these methods are provided in the links below. Verifying their correctness can be done by comparing the results from the parallel version versus the no-parallel result.
Independent Streams. Leapfrogging and Block-Splitting
