The number of cores in modern processor is growing. For quite a while we were stuck at 2 or 4 cores. But, lately the number of cores have grown to 6 and 8 even for consumer processors, and to 14 cores for Intel Xeon workstation and cloud CPUs, and 32 cores for AMD desktop and cloud processors.
It’s a common practice for multi-core programming to have a threshold for when to switch between single core code and multi-core code. This threshold is for the amount of work that is large enough for multiple cores to be used and to provide performance gain. However, this single threshold isn’t sufficient for 2-core processor and 32-core processor. We need a way that handles even hundreds and thousands of cores.
One possible way is to determine the minimal amount of work, such as array size, that is big enough for two cores to provide a speedup over a single core. Think of it as the amount of work which is large enough for two workers to be faster than a single worker. The same idea can then be scaled to more than two workers. As the amount of work grows, more workers are brought in to help, when the result is faster than doing the work with fewer workers.
This methodology ramps up the number of workers/cores when there is sufficient amount of work to utilize these workers/cores to provide a performance gain.
This ramp up methodology has been implemented and tested in the HPsharp C# nuget package and is available now. It is used effectively in the Parallel Merge Sort functions (SortMergePar), which provides a smooth ramp from using a single core to using all of the cores, as the array size grows, scaling performance smoothly and always performing better than a single-core algorithm.
Too Little Work For Too Many Workers
The easiest parallelism approach for C# developers to use is to add .AsParallel().Sort() or .AsParallel().ToArray(), which throws all of the cores at the problem, no matter the size of the operation. Here is an example of what happens to List.AsParallel().ToArray() on a 6-core CPU.
!!! Add Graph Here showing slow down in performance!!!
As seen in the benchmark graph above, performance suffers significantly when parallelism is applied to too small of a problem. In this case, the problem is too small to be processed efficiently by all of the cores. Kinda like too many workers with too little work to do. The overhead of each worker/core is hurting performance. It is better to use fewer workers/cores.
The same issue occurs in HPCsharp for List.CopyTo(), which copies a List of Int32’s to an existing array, as shown by two benchmarks: one running on a 14-core Xeon processor, and another on a 6-core laptop processor
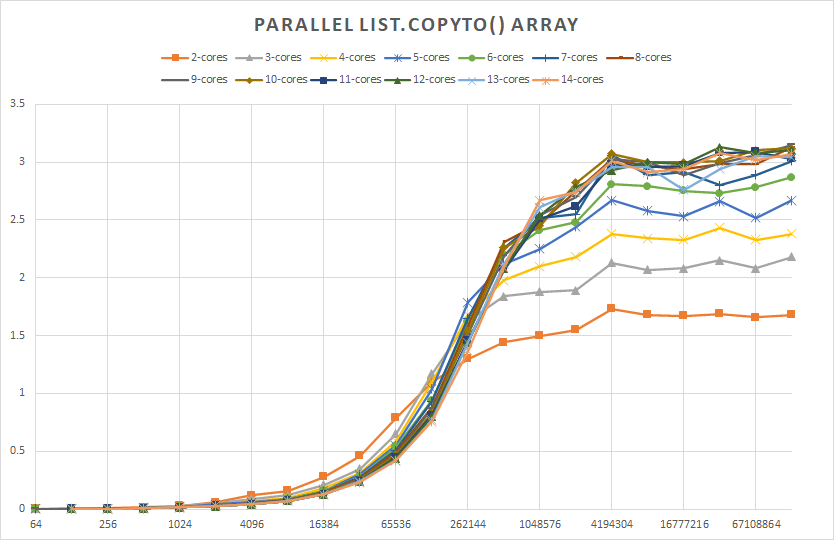
The vertical axis indicates the speed-up obtained when using multi-core List.CopyToPar() of HPCsharp nuget package, comparing to a single core. Greater than 1 means faster, and less than 1 is slower. This benchmark shows several interesting observations:
- List size must be 256K or larger to benefit from parallelism, for this copy operation, even for two cores
- Small List sizes experience severe performance degradation, 64 element List is about 500X slower as a multi-core copy, versus a single core copy
- Two, three, or even four cores are not sufficient to use all of the available memory bandwidth on the Xeon processor with 4-channels of memory. 7 cores are needed to reach the peak performance.
- Using more than 7 cores does not result in performance increase, and is wasteful, causing a slight performance degradation, most likely due to contention.
- 3X performance increase is possible for List.CopyToPar() by using 7 cores, and 4 Million or bigger List sizes.
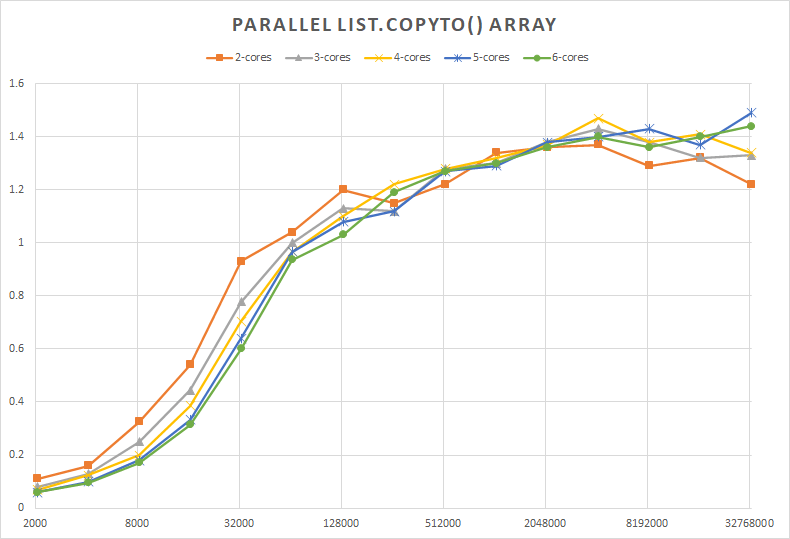
Benchmark on a 6-core laptop processor shows:
- List larger than 128K is needed to show performance gain for parallel copy
- Using more than 2 cores does not show gains in performance, on this two memory channel processor
- Performance also peaks at about 4 Million List size
- 40% performance gain is possible for a parallel copy
- Small arrays cause severe performance degradation for parallel copy
As developers, we don’t want to think about, “Is this case too small for parallelism?” We want the algorithm to scale parallelism as it needs to and do it efficiently thru a simple interface.
Efficiency for Large Arrays
At the other end of the spectrum, when arrays are very large, we’d like performance to be maximized. In this case, there is so much work that there is no question about needing all of the available workers. There is more than plenty of work to go around for everyone. In fact, we would love to have more workers, but we just don’t have any more available.
In this case, to minimize overhead of switching between workers, we can simply split the array into M chunks for M available workers. All of the workers get the same amount of work. This method has been benchmarked for the Parallel Merge Sort algorithm, resulting in peak performance.
When the array was broken into smaller chunks, performance went down. When fewer workers/cores were used, performance also decreased.
The above method is included in the Parallel Merge Sort algorithm implementation of the HPCsharp nuget package on http://www.nuget.org
The Parallel Merge Sort algorithm handles small array sizes efficiently by ramping up the number of cores/workers from one to the maximum available. It also handles large array sizes efficiently by splitting the array evenly among the workers, which minimizes overhead.
More Sophistication
The above method of splitting the array into equal chunks for each core to process is as simple as it can be, following the KISS principle – “Keep it Simple Stupid” – requiring any additional complexity to have a justification.
However, when the array size is large enough, it won’t perform as well under the case where one of the cores gets interrupted to do something else for a while. In this case, other cores will get their work done and then will wait for the last core to finish its chunk.
A better way is to split the work into large enough chunks where the overhead cost of switching between workers/cores is negligible. This allows other workers to pick up the slack, in case if one or more workers/cores are not finished with their work yet.
This level of sophistication will be added to HPCsharp soon…

The analysis is too simplistic. In general the relationship of throughput to cores is linear only at low number of cores. As the number of cores (sharing the same computer memory) increases, they begin to interfere with each other (due to memory data accesses). This means that as N increases the incremental benefit of adding more cores decreases and at some point adding more cores actually hurts.
My experience shows that the performance gain of parallelism is an upside down parabola. At low cores it is linear going up. It begins to flatten at some level of parallelism and then actually declines.
LikeLike
Good feedback David. This blog is just the beginning, describing a method that can use more sophistication. It can definitely use your insight into variety of algorithms, and needs to be taken on case-by-case basis, generalizing to a curve that flattens out and most likely drops when contention leads to reduce in slope and then drop in performance.
For a few algorithms that I’m working with, the linear model will work adequately, as the main optimization these need is around small sized array, where always using all of the cores leads to poor performance. On the larger array size, using too many cores, leads to less performance loss, but is wasteful, possibly from power point of view. This is exactly the kind of discussion and design I’ve been hoping to get to, with some real measurements to back them up.
We’ll both have to think about how to make these kinds of curves of performance behavior for various parallel algorithms available so that the algorithms can use these curves to determine the optimal core usage for the size of the problem.
One result I’m seeing with memory-bound algorithms is that it just about never pays to have the degree of parallelism be higher than the number of physical cores. Another important factor is the number of memory channels, obviously for memory-bound algorithms, as you’ll see from some of the benchmarks I’ll publish shortly.
LikeLike