NVIDIA has implemented several pseudo-random number generation (PRNG) algorithms that run on its family of powerful Graphics Processor Units (GPU). The GPU accelerates these algorithm by running them on its many computational cores, taking advantage of parallel computation, local embedded memory and high bandwidth external memory.
The following graph compares performance of these algorithms, generating 1 Billion single precision and double precision floating-point random values in graphics memory, running on an NVIDIA GeForce 950M GPU in a sub-$1,000 laptop, using CUDA 8.0:
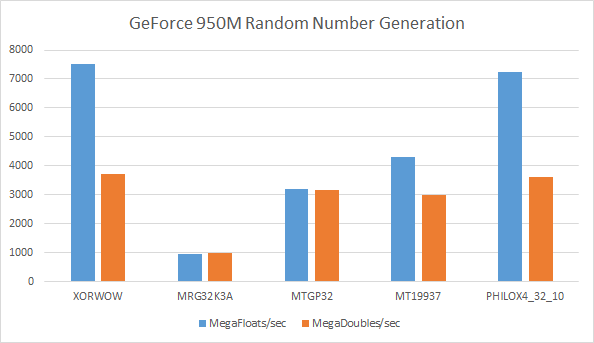
Each random number generated is in the range of 0.0 to 1.0, with uniform distribution. The two fastest algorithms (XORWOW and PHILOX) generate over 7 GigaFloats/sec. Interestingly, two of the algorithms generate single precision random values nearly twice as fast as the double precision values, two algorithms generate both at nearly the same rate, and one is somewhere in between.
NVIDIA also makes powerful desktop GPUs, which contain a higher number of computational cores as well as faster external memory. The following graph compares random number generation algorithms running on the GeForce 1070 GPU in a desktop system:
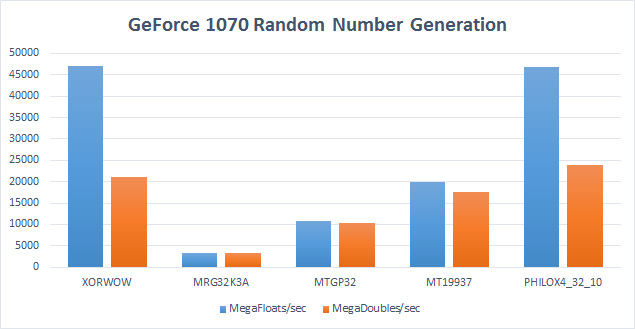
The GeForce 1070 is substantially faster than the GeForce 950M at generating random numbers, with over 46 GigaFloats/sec. The following graph shows a comparison between the two graphics cards:

GeForce 1070 is at least 3X faster for all algorithms for single and double precision random values, and is over 6X faster for two out of the six algorithms.
These benchmarks show that GPUs are very powerful at generating single and double precision random values in graphics memory, and have large amount memory to hold these values. If these values need to be transferred to system memory, this will take time and will impact performance. We will explore this in future posts and compare performance to various CPU random number generators.
NVIDIA cuRAND
All of the results above used NVIDIA cuRAND library, which is introduced on cuRAND Library Webpage. Performance measurements are substantially higher on this blog for GPU (cuRAND) and CPU (MKL) due to being more up to date with the versions of cuRAND and MKL, as well as running on newer hardware.
